A Brief History Of Vision Transformers:
Di: Jacob
Vision-Language Models: An Introduction.

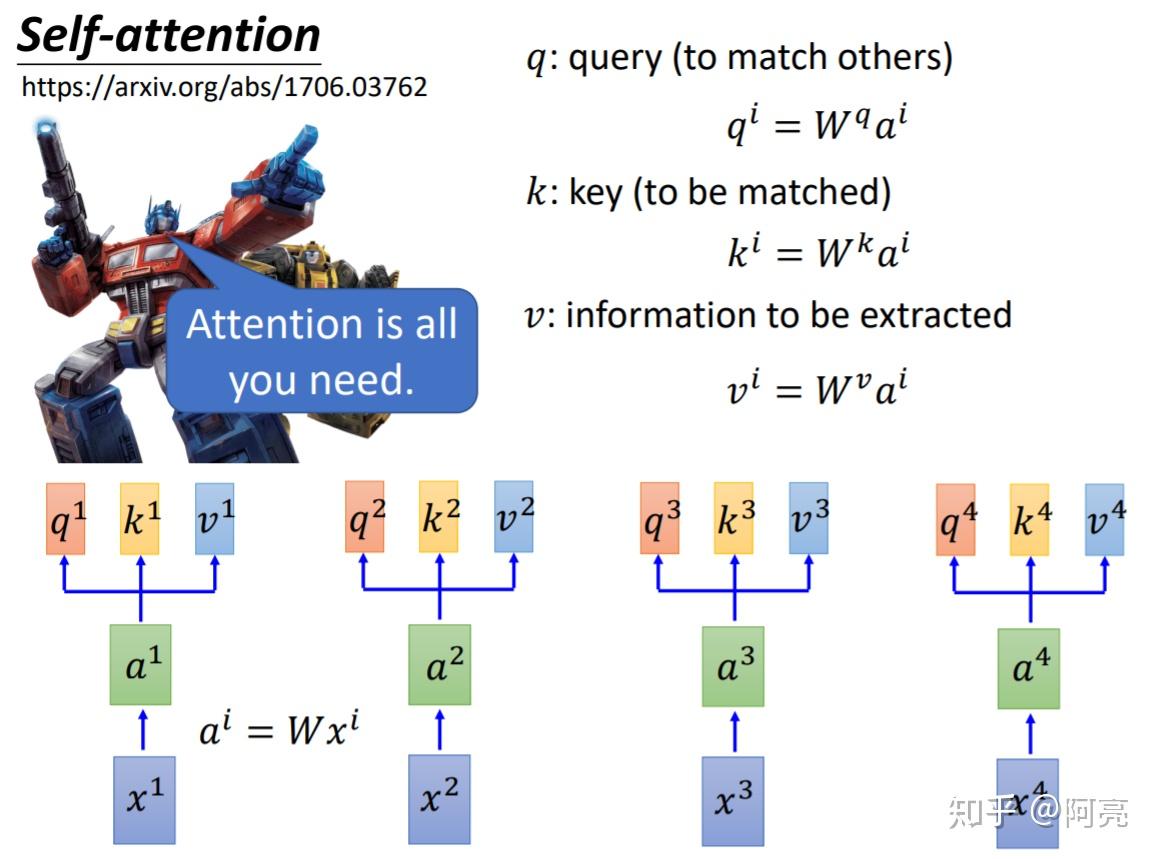
Transformer, first applied to the field of natural language processing, is a type of deep neural network mainly based on the self-attention mechanism. In the past, most of the review papers summarized Transformers in . Recent ICCV 2021 papers such as cloud transformers and the best paper awardee Swin transformers both show the power of attention mechanism being the new trend in image tasks.The transformer architecture, which was initially developed for natural language processing (NLP), is modified for image-related applications via vision transformers. RANSFORMERmodels [1] have recently demonstrated exemplary performance on a broad range of language tasks e.
1), along with a summary of seminal Transformer 1.
A brief history of the Transformer architecture in NLP
In this work, we propose a novel view of ViTs showing that they can be seen as ensemble networks containing multiple parallel paths with different lengths. Attention mechanisms combined with RNNs were the predominant architecture for facing any task involving text until 2017, when a paper was .
Vision transformer
This information is then transmitted to a fully connected (FC) layer, which concludes with a softmax layer to provide the probability of belonging to each class.The main categories we explore include the backbone network, high/mid-level vision, low-level vision, and video processing. Since Transformer has a more powerful representation ability than Convolutional Neural Networks (CNN), researchers are trying to apply it to computer vision tasks.A brief history of Transformers. Vision transformers (ViTs) are quickly becoming the de-facto architecture for computer vision, yet we understand very little about why they work and what they learn.Transformers in Vision: A Survey Salman Khan, Muzammal Naseer, Munawar Hayat, Syed Waqas Zamir, Fahad Shahbaz Khan, and Mubarak Shah Abstract—Astounding results from Transformer models on natural language tasks have intrigued the vision community to study their application to computer vision problems.This is a visual guide to Vision Transformers (ViTs), a class of deep learning models that have achieved state-of-the-art performance on image classification tasks.Transformer, a new type of neural network based on the self-attention mechanism, has revolutionized the field of natural language processing.fundamental concepts behind the success of Transformers i. Though originally developed for NLP, the transformer architecture is gradually making its way into many different areas of deep learning, including image classification and .Computer vision transformers often employ CNN architectures with transfer learning techniques like fine-tuning and layer freezing to enhance image classification performance, surpassing traditional machine learning models. Self-attention and the Vision Transformer. In a variety of visual benchmarks, transformer-based models perform similar to or better than .Abstract: A recent trend in computer vision is to replace convolutions with transformers. Thanks to its strong representation . This guide will walk you through the key components .The Vision Transformer (ViT) model was proposed in An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby., retain as high as 60% top-1 .1 The vision Transformer architecture.Recently, the intersection of Large Language Models (LLMs) and Computer Vision (CV) has emerged as a pivotal area of research, driving significant advancements in the field of Artificial Intelligence (AI). Among their salient benefits, Transformers enable modeling long dependencies between input sequence elements and support parallel processing of sequence as compared to recurrent networks e. The definitive guide to LLMs, from architectures, pretraining, and fine-tuning to Retrieval Augmented Generation (RAG), multimodal Generative AI .However, as vision transformers (ViTs) do not employ convolutions to extract image information, these methods need to be adapted for ViT models. We then cover extensive applications of . Publisher (s): Packt Publishing. Author (s): Denis Rothman.The best way to understand where transformers stand in the current state-of-the-art of AI is by understanding the history of Natural Language Processing (NLP) which is how transformers . Firstly, it provides a comprehensive overview of a recommended architecture for using vision . 2021) as shown in Figure 1. ISBN: 9781805128724. It’s the first paper that . Discover Vision-Language Models’ (VLMs) transformative potential — merging LLM and computer vision — for practical applications in., self-attention, large-scale pre-training, and bidirectional feature encoding. In our survey, we determined . And in 1886, William Stanley built a transformer that provided electrification to stores and office spaces. You know (the basics of) PyTorch; You understand the Transformer concept; You know (more less) how BERT works ([CLS] token) Overview .

Explore head-based image classification with Vision Transformers.Transformers have had a significant impact on natural language processing and have recently demonstrated their potential in computer vision.In 1881, Lucien Gaulard and John Dixon, from Paris, invented the first commercially successful transformer.A brief history of transformers; Why using transformers for CV is complicated? How Vision Transformer (ViT) works? ViT performance in image classification; Critics, impact, and my predictions (the fun part) Assumptions. introduce a Vision Transformer based on. This paper presents a .
A Survey of Visual Transformers
This architecture consists of a stem that patchifies images, a body based on the multilayer Transformer encoder, and a head that transforms the global representation into the output label. Vision Transformers apply .
Vision Transformers in PyTorch
Image classification involves assigning a label or category to an input image 1. Due to the powerful capability of self-attention mechanism in transformers, researchers develop the vision transformers for a variety of computer vision tasks, such as image recognition, object detection, image segmentation, pose estimation, and 3D reconstruction.Abstract—Astounding results from Transformer models on natural language tasks have intrigued the vision community to study their application to computer vision problems. However, the performance gain of transformers is attained at a steep cost, requiring GPU . In this article, we will retrace the key moments in Transformers’ evolution, emphasizing their impact on popular culture.Transformers are a type of machine learning which unlocked a new notion called attention that allowed models to track the connections between words (for example) across pages, chapters, and books . Furthermore, we also take a brief look at the self-attention mechanism in computer vision, as it is the base . Navendu Brajesh. Learn how ViT applies to image patches for object recognition. It was released on March 14, 2023, and has been made publicly available in a limited form via ChatGPT Plus, with access to its commercial API being provided via a waitlist.?️ The Transformer architecture has revolutionized Natural Language Processing, being capable to beat the state-of-the-art on overwhelmingly numerous tasks!.low, we provide a brief tutorial on these two ideas (Sec. Specifically, we equivalently transform the traditional cascade of multi-head self-attention (MSA) and feed-forward network (FFN) into three parallel . They have shown promising results over .In this survey, we have reviewed over 100 of different visual Transformers comprehensively according to three fundamental CV tasks and different data stream types, where taxonomy is . In a CNN, spatial information is extracted from convolutional filters. Transformers in Vision: A Survey.1007/s10462-023-10595-0 Corpus ID: 258741280; A survey of the vision transformers and their CNN-transformer based variants @article{Khan2023ASO, title={A survey of the vision transformers and their CNN-transformer based variants}, author={Asifullah Khan and Zunaira Rauf and Anabia Sohail and Abdul Rehman and Hifsa Asif and Aqsa Asif and Umair Farooq}, . Vision Transformers apply the transformer architecture, originally designed for natural language processing (NLP), to image data.1 Transformers in Vision: A Survey. 11 min read · .Astounding results from Transformer models on natural language tasks have intrigued the vision community to study their application to computer vision problems.The Vision Transformer has sparked a surge of interest in Transformers applied to applications in vision since its introduction in October 2020 ( Dosovitskiy et al.Andere Inhalte aus medium.Computer vision community in recent years have been dedicated to improving transformers to suit the needs of image-based tasks, or even 3D point cloud tasks. 12 min read · Oct 19, 2022–2.The history of Transformers is a journey from Japan to the rest of the World and back.comA Brief History of Vision Transformers – Medium
A Brief History of Vision Transformers
A vision transformer (ViT) is a transformer designed for computer vision.In this paper, we have provided a comprehensive review of over one hundred different visual Transformers for three fundamental CV tasks (classification, detection, and segmentation), . The transforming robots have revolutionized the toy industry, generating a phenomenon that has inspired TV series, movies and comics.
, text classification, machine translation . Salman Khan, Muzammal Naseer, Munawar Hayat, Syed Waqas Zamir, Fahad Shahbaz Khan, and Mubarak Shah. As transformers have become the backbone of many state-of-the-art models in both Natural Language Processing (NLP) and CV, understanding their evolution and potential .
A Visual Guide to Vision Transformers
We surveyed the applications of Vision Transformers in different areas of medical computer vision such as image-based disease classification, anatomical structure segmentation, .
Building the Vision Transformer From Scratch

We also include efficient transformer methods for pushing transformer into real device-based applications.Thanks to its strong representation capabilities, researchers are looking at ways to apply transformer to computer vision tasks. Convolutional neural networks (CNNs) have several potential problems that can be resolved with ViTs.Since then, numerous transformer-based architectures have been proposed for computer vision. it has numerous real-world applications, some of which include Medical Diagnosis, Autonomous Vehicles, Surveillance, E-commerce, Agriculture, Quality Control, and Security.To overcome the partial loss of spatial information at patch borders as well as tackling the quadratic computational complexity of ViT, Liu et al. Thanks to its strong representation capabilities, researchers are looking at ways to apply transformer to computer vision tasks.Schlagwörter:Computer VisionViT
Vision Transformer: What It Is & How It Works [2024 Guide]
This article walks through the Vision Transformer (ViT) as laid out in An .Transformers have achieved great success in natural language processing. To this end, we give an in-depth review of the vision-based transformer.In this survey, we have reviewed over one hundred of different visual Transformers comprehensively according to three fundamental CV tasks and different data stream types, .Generative Pre-trained Transformer 4 (GPT-4) is a multimodal large language model created by OpenAI and the fourth in its GPT series. However, the performance generally remains
Vision Transformer
1 INTRODUCTION. For image coding tasks such as compression, super-resolution, segmentation, and denoising, different variants of ViTs are used. In this example, an image is . A ViT breaks down an input image into a series of patches (rather than breaking up text into tokens), serialises each .Image classification is a fundamental task in computer vision. In a variety of visual benchmarks, transformer-based .Transformer is widely used in Natural Language Processing (NLP), in which numerous papers have been proposed. Working of Transformer.A Brief History of Vision Transformers: Revisiting Two Years of Vision Research. Among their salient benefits .Title: Transformers for Natural Language Processing and Computer Vision – Third Edition.We show and analyze the following intriguing properties of ViT: (a) Transformers are highly robust to severe occlusions, perturbations and domain shifts, e.As a special type of transformer, vision transformers (ViTs) can be used for various computer vision (CV) applications. In this paper, we . Abstract—Astounding results from transformer models on natural language tasks have intrigued the vision community to study their application to computer vision problems.Several recent Vision Transformers demonstrate that the model can be learned end-to-end on ImageNet-1K without any dedicated pre-training phase [35]–[37]. This review paper contributes in three main ways. As a transformer, GPT-4 was pretrained .
A Brief History of Vision Transformers:
However, there are few papers to give a comprehensive survey on the vision-based transformer.

Transformer deals with the alternating current, which flows through electric wires creating a fluctuating . Release date: February 2024.
(PDF) A Survey of Visual Transformers
Recently, the transformer has been borrowed for many computer vision tasks. While existing studies visually analyze the mechanisms of convolutional neural networks, an analogous exploration of ViTs remains challenging.Vision Transformers (ViTs) are normally regarded as a stack of transformer layers.
- Winterjacken Mädchen Günstig Online Kaufen
- Stellenangebote Von Emporium-Merkator Münzhandelsgesellschaft Mbh
- Ypsilon In Der Geschichte – Alphabet
- The Best Small Dog Names : 151 Best Pet Names for Dogs, Cats, Fish, Birds and More in 2024
- Oberholtzer’S Kentucky Sorghum, 42 Ounce
- Alle Elektro-Diffuser Produkte
- Wohnmobil Lackierung : Wohnmobil-Lackierung
- Übungen Regelmäßige Und Unregelmäßige Verben
- Airlie Beach: 2-Day Whitsunday Islands Sailing Snorkel Tour
- 131 Häuser Kaufen In Der Gemeinde 59457 Werl
- Ärztliche Bereitschaftspraxis Harlaching
- Asics Move Every Mind Study Report V2