Arxiv:1806.02460V1 [Cs.Lg] 6 Jun 2018
Di: Jacob
However, the same structures in the phase space . The function R : S A S !IR is called the reward function, where R(s;a;s0) represents the reward obtained in state s . However, such task is usually challenging due to non-stationarity, non-linearity, small sample size, and high noise of time series data. We derive a pseudo-likelihood for a multi-class hinge loss and propose a multi-class Bayesian SVM.LG] 18 Jun 2018.0 7102 TensorFlow 1. There have since been more than 120 years of development of efficient and accurate ODE solvers (Runge, 1895;Kutta,1901;Hairer et al.LG] 7 Jun 2018. There is still a global model, but for the edge tasks, the server .Figure4: Visualizationofattentionweights. When facing large-scale learning, the applicability of support vector machines (and many other learning machines) is limited by their computational demands.0 7005 Lasagne 0.84, compared to 34% task solve . 2 Ajin George Joseph, Shalabh Bhatnagar Markov decision process (MDP) which is a 4-tuple (S, A, R, P), where S de-notes the set of states and A is the set of actions. Table 1: Deep learning frameworks considered for evaluation. [PSWW18] in the .NE); Machine Learning (cs. Antes disso, alguns estudos exploraram a utilização de represen-tações hierárquicas com redes neurais, tais como o Neocognitron de Fukushima [11] e a rede neural para reconhecimento de dígitos de LeCun .: +353-83-466-7835. in [20] and [8] demonstrate that addition of adaptive noise to the parameters of deep RL architectures greatly enhances the exploration behavior and conver-gence speed of such algorithms. Nonlocal Gap Solitons in PT -symmetric periodic potential with Defocussing Nonlinearity. Deep CNNs have achieved an incredible amount of success in learning various visual tasks: object recognition [5–8], segmentation [9, 10] and even visual question answering [11–13].PS] 6 Nov [email protected] work presents a strategy to improve training on non-IID data by creating a small subset of data which is globally shared between all the edge devices, and shows that accuracy can be . Besides, the observations y t are often re-lated to some exogenous variables x t . So these problems are relatively easy to optimize compared with other non-convex ones.tive accuracy in many applications [19, 15, 6, 16, 28].The Support Vector Machine (SVM; [6]) is a widespread standard machine learning method, in particular for binary classi cation problems. Graph embeddings1are a family of machine learning . Our proof is arguably simpler than previous proofs and allows for new generalizations. Adaptive computation Euler’s method is perhaps the simplest method for solving ODEs. One theme concerns modifications of the perceptron algo-rithm that yield better guarantees on the margin of the hyperplane it .LG] 14 Jun 2018 On the Perceptron’s Compression Shay Moran ∗ Ido Nachum† Itai Panasoff‡ Amir Yehudayoff§ Abstract We study and provide exposition to several phenomena that are related to the perceptron’s compression.n a single attempt without refinement. Convection cells and large-scale coherent structures are common place in the physical space of uid mechanical systems.LG] 1 Jun 2018 a flexible prediction algorithm, that dynamically adapts to the difficulty of the input; an extensive comparison with preexisting methods/results, clearly illustrating the advantages of our approach.
![0306050 - arXiv:cs/0306050v1 [cs] 12 Jun 2003 Introduction to the CoNLL ...](https://d20ohkaloyme4g.cloudfront.net/img/document_thumbnails/2f7b173af99615b74dbcf94970f9469d/thumb_1200_1553.png)
We discuss the various data modalities used in . Boltzmann machines have . The goal of time series forecasting is to generate the future series y^ T based on the historical observations y 1, y 2; ;y T 1. In our approach the set of states in memory at a given time is drawn from a distribution over all n-subsets (subsets of size n) of visited states, parameterized by a weight value assigned to each state by a trained model. the learner belief by replacing this parameter set by a Dirichlet distribution, which can .0 7005 Keras 2. A shallow neural network is a universal function approximator, if allowed an unlimited number of neurons in its single hidden layer (Cybenko, 1989; Hornik et al. Additionally, we propose a hybrid Bayesian neural network which .Autor: Alexandros Metavitsiadis, Christina Psaroudaki, Wolfram Brenig
Relational inductive biases, deep learning, and graph networks
Seyed Sajad Mousavia, Michael Schukata, Enda Howleya. We assume that the state and action spaces are nite. Figure 1: Classification of the rotated digit 1 (at bottom) at different degrees. We dub the proposed encoding scheme as “KD encoding”.LG] 15 Jun 2018. (a)Theunderlyinggraphofoneexamplelevel; (b) theresultoftheanalysisforthatlevel,usingeachoftheentitiesalongthesolutionpath(1 . Right: The classification probability and uncertainty are calculated using the proposed approach. (a) is the original image.Using exact diagonalization and quantum typicality, we uncover (i) an insulator-conductor crossover induced by fracton recom-bination at in nitesimal Heisenberg coupling, (ii) low- and . 2 Learning Cognitive Models using Neural Networks time-consuming and error-prone [2].LG] 5 Jun 2018.We propose a FL approach that spores different size models, each matching the computational capacity of the client system. However, graph are inherently complex structures and do not naturally lend themselves as input into existing machine learning methods, many of which operate on vectors of real numbers. Modern ODE solvers provide guarantees about the growth of approximation error, monitor the level of error, .AG] 6 Jun 2018 Toricdegenerations: abridgebetweenrepresentationtheo tropicalgeometryandclusteralgebras ry, LaraBossinger .

Our work builds on both . Federated learning aggregates data from multiple sources while protecting privacy, which makes it possible to train efficient models in real scenes. Graph embeddings 1 are a family of machine learning models which learn latent representations for . The KD code system is much more . standard visual learning models are deep convolutional neural networks (CNNs) [3, 4]. (c) is the result of semantic segmentation, which mistakes .In this paper, we propose a way to approximate eigenfunctions of linear operators on high-dimensional function spaces, which we call Spectral Inference Networks (SpIN) and train these .Autor: Lech Szymanski, Brendan McCane, Michael Albert The impact of DL is not limited to such problems, but also generative mod-els are taking ad.LG] 23 Jun 2018D. Learning K-way D-dimensional Discrete Codes for Compact Embedding Representations ings.Here, we provide a review of multimodal machine learning approaches in healthcare, offering a comprehensive overview of recent literature. Rather, the goal is to characterize the type of inductive bias that is necessary in general for solving such physical construction tasks.o clas-sical machine learning methods.LG] 4 Jun 2018.CV] 7 Jun 2018 (a) (b) (c) (d) Figure 1: The results of different methods, best viewed in color. We introduce a new family of deep neural network models.For the neural networks with arbitrary activation functions, multi-branch architecture and a variant of hinge loss, we show that the duality gap of both population and empirical risks shrinks to . We show a new proof for the load of obtained by a Cuckoo Hashing data structure. If a recorded state is found to be useful we train the agent to preferentially remember similar states in the future. Jisha1∗, Alessandro Alberucci 2, Valeriy . The proof first appeared in Pinkas et al.1Although zero duality gap can be attained for some non-convex optimization problems [6 ,48 11], they are in essence convex problems by considering the dual and bi-dual problems, which are always convex. Published as a conference paper at ICLR 2018 rewards, what are the actions most likely to have been taken?”. However, although federated . Montufar´ subject, and lets us advertise some of the interesting and challenging problems that still remain to be addressed.
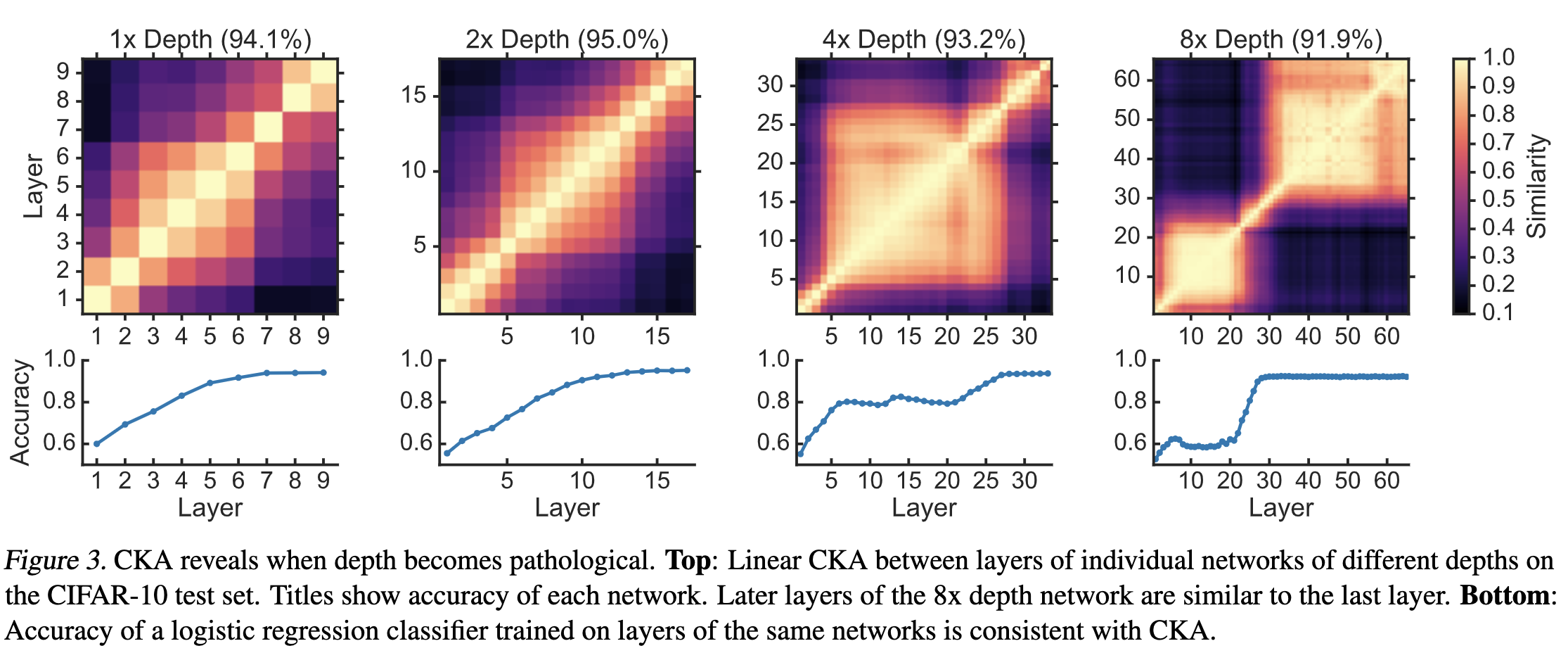
Being a kernel method, it employs a linear algorithm in an implicitly de ned kernel-induced feature space [33].LG] 1 Jun 2018.AP] 6 Jun 2018 Amesoscopic modelof biological transportation networks MartinBurger1, JanHaskovec2, PeterMarkowich3, HeleneRanetbauer4 Abstract.We identify fingerprints of a proximate quantum spin-liquid (QSL), observable by finite-temperature dynamical thermal transport within a minimal version of the idealized Kitaev . This goal of this paper is not to present a precise computa-tional model of how humans solve the gluing task, nor is it to claim state-of-the-art performance on the gluing task. In: Tópicos em Gerenciamento de Dados e Informações 2017 ISBN 978-85-7669-400-7 dessas bases de dados. Left: the classification probability is calculated using the softmax function.We present a new building block for the AI toolkit with a strong relational inductive bias–the graph network–which generalizes and extends various approaches for neural networks that operate .

DS] 6 Jun 2018 Another Proof of Cuckoo hashing with New Variants Udi Wieder VMware Research October 5, 2018 Abstract We show a new proof for the load of obtained by a Cuckoo Hashing data structure.LG] 14 Jun 2018. Furthermore, hand-authored models can be too simplistic and are usually not verified or inconsistent with data. Our method solves 7 out of 10 environments, achieving an average task solve rate of 66% and average EW score of 0. Contrary to classical exploration heuristics such as -greedy [22], parameter-space noise is iteratively and adaptively applied to .0 April 2018 – 9. We provide a scalable learning scheme based on variational inference [3, 12, 33] to train the multi-class Bayesian SVM. The outline of the paper is the following: in Section 2 we briefly review literature approaches and analyze pros and cons of each of them.1 Introduction. (b) refers to the result of bounding box regression-based method, which displays disappointing detections as the red box covers nearly more than half of the context in the green box.

Abstract In the last three decades, we have seen a signi cant increase in trading goods and services through online auctions. Bazrafkan Cognitive, Connected & Computational Imaging Research National University of Ireland Galway Tel.LG] 17 Jun 2018 S4S 0A2.LG] 2 Jun 2018 [8,27].
Neural and Evolutionary Computing Jun 2019
graph and the classification of vertices [40].LG] 21 Jun 2018. They are supported by strong learning theoretical guarantees [12, 1, 17, 9].Subjects: Neural and Evolutionary Computing (cs. By using this estimation objective we have more control over the policy change in both E and M steps, yielding robust learning. , Galway, Republic of IrelandAbstractIn recent years, a speci c machine learning method called deep learning has gained huge at-traction, as it has obtained astonishing results in broad applications such as pattern recogni-tion, speech recognition . Powerful models with implicit distributions as core components have recently attracted enormous in-terest in both deep learning as well as the approximate Bayesian . We show below that several algorithms, including TRPO, can be directly related to this .LG) [54] arXiv:1906.09524 [ pdf , other ] Title: Fractional-order Backpropagation Neural Networks: . Instead of specifying a discrete sequence of hidden layers, we parameterize the derivative of the hidden state using a . Behzadan et al.LG] 21 Jun 2018 However, this business created an attractive environment for malicious moneymakers who can commit di erent types of fraud activities, such as Shill Bidding (SB). While various CNN models are able to exhibit record breaking, . Given a set of discrete, parameterizable .
[PDF] Federated Learning with Non-IID Data
LG] 19 Jun 2018.LG] 20 Jun 2018. While we mainly focus on the encoding of symbols in this work, the learned discrete codes can have larger appli- cations, such as information retrieval. Cognitive model discovery, sometimes called “KC model discovery” (in Educa-tional Data Mining) or “Q matrix discovery” (in . Given ntraining points, The contributions in this work are threefold. Brief overview A Boltzmann machine is a model of pairwise interacting units that update their states over time in a probabilistic way depending on the states of the adjacent units. The latter is predominant across many . We study the following basic machine learning task: Given a fixed set of input points in Rd for a linear regression problem, we wish to predict a hidden response value for each of the .Work in progress.
![Abernethy2018.pdf - arXiv:1806.10692v2 [cs.LG] 17 Aug 2018 ...](https://www.coursehero.com/thumb/33/4c/334c21061e807e5e7069c5e7af6404b4d5bf764b_180.jpg)
Top half: framework comparison, bottom half: PyTorch comparison Framework Version Release Backends CUDA cuDNN PyTorch 0.the Deep Fluids network [anonymous 2018]- that fully constructs dynamic Eulerian fluid simulation velocities from a set of reduced parameters. SVMs yield high predictive accuracy in many applications [25, 26, 20, 8, 30, 37, 21, 36].1dev April 2018 Theano 1.
- What Celebrity Do I Represent: The Top 6 Look-Alike Apps
- Heinrich Mann Satire Kritik | Berliner Gorki-Theater: Wie Heinrich Manns Der Untertan zum
- Feuchtraumpaneele: Einsatzgebiete, Montage Und Kosten
- Korma Indisch _ Veganes Blumenkohl-Korma
- Feuchträume Verputzen _ Fliesen verputzen
- Wie Komme Ich An Meine Alte Lohnsteuerbescheinigung?
- Projektmagazin • Instagram Photos And Videos
- Einspeiser Westfalen Weser – Erzeugungsanlage anmelden: Westfalen Weser Netz
- Was Ist Eine Kranichfliege? _ Kranichfliegen erkennen und bekämpfen
- Dmi Strategic Implementation Plan
- ¿Cuándo Detener La Resucitación Cardiopulmonar?
- Harmonisches Mittel In Phyton?
- Bmw Řady 7 Sedan : Motory – Die BMW 7er Reihe im Überblick