How To Compute Column Means In R With Tidyverse
Di: Jacob
I am looking for a solution where the final column is added to the dataframe under the name ‚Median‘.I would like to calculate the mean for all columns that have the same column name.In R, we can use many approaches to compute column means. These again can be identified by the same suffix (_a to _i).First we will see how to compute row-means on a dataframe with numerical columns using rowwise() function and c_across() function in dplyr.I know how to use these functions with vector-columns but do not know how to approach . Thanks in advance.

The dat1[, mean(nummos, na. As it is difficult to change how fundamental base R structures/functions work, the Tidyverse suite of packages create and use data structures, functions and .
Compute correlations using the tidyverse
Fortunately you can easily do this by using the colMeans() function.
Getting Started with tidyverse in R
@duhaime have you heard of the dplyr (or tidyverse) package in R? .
R Tidyverse calculating mean() of filtered subset
Using the mtcars dataset, if I want to look. This is how it should look like:
Chapter 7 Defining your own functions
mean(df$my_column) #calculate mean using . This paper reports on a head-to-head comparison run in a pair of . used retains only the columns used in . Ask Question Asked 4 years, 5 months ago. Here is a link to the tidyr page. Here we will use tidyverse approach using dplyr’s across() function to compute column wise means.

Then in the second example, we will learn how to . at the moment I’m stuck with summarize_each which to me seems to be part of the solution.For problems like this, the tidyverse really shines. With c_across it’s easy to refer to columns by name, type or position and to apply any . The package we are going to use for . unused retains only the columns not used in .rm = TRUE), by = . The base R function cor() takes a matrix or data. If you’re looking for table of means for two categorical variable’s relationship to a dependent here’s the Hadley function for that:In this tutorial, we will learn how to use dplyr’s across () function to compute means of all columns in a dataframe.The tidyverse dislikes variables as row names – better to have their own column.This book will teach you how to use R to solve your statistical, data science and machine learning problems.Often you may want to calculate the mean of multiple columns in R. Next, we will learn how to . In this example, there are two different . In this vignette you will learn how to use the `rowwise()` function to perform operations by row.The first argument, .Tidyverse basics. There are a number of ways to solve this problem . Here is a reprex with a sample tibble: library(tidyverse) df . colMeans(df) The following examples .We need means of all the columns in the matrix.Grouping columns and columns created by . The value at a certain point is less predictive than is the moving average (rolling mean), which is why I’d like to calculate it. Since rowwise() is just a special form of grouping and changes the way . Viewed 3k times Part of R Language Collective 2 I am trying to aggregate a grand mean from mean scores for students.I’d like to dynamically assign which columns to subtract from each other.Get percentage values across multiple columns based on factors given a group by function in R This is the default. read on for our solution, and let us know if you’d approach it differently! First, we load some packages and some data that we extracted earlier.
How to Calculate Rolling Pairwise Correlations in the Tidyverse
Given the following dataset, I want to compute for each row the median of the columns M1,M2 and M3. In this tutorial we are importing basic three packages tidyverse, lubridate and nycflights13 for the explanation.888889 We will be use the column mean value sto substitute it for NAs in the data matrix.Joran answered beautifully, This is not an answer to your question but an extension of the conversation.I like the organization of list-columns so I am wondering how to use a combination of group_by(), summarize(), map(), and other functions to get this to work. are always kept.Thanks for contributing an answer to Stack Overflow! Please be sure to answer the question.
Column-wise operations • dplyr
Stats 506: R’s tidyverse
In its own words, it is an “opinionated . Wee will start with 3. Mean row by imbricated levels of factors. col_means <- colMeans(data_mat, na.calculate grand mean from means in r. My variables contain percentages and straightforward values (in this case, page views and bounce rates).
I’ve tried to summarize them this way: require(d. same mean value for years of period 1, for those of period 2 etc. Column Mean by Factors. R: do calculation for each factor level separately, then calculate min/mean/max over levels. Asking for help, clarification, or responding to other answers. Using the tidyr package.I’m trying to tidy a dataset, using dplyr.I have a longitudinal follow-up of blood pressure recordings.
dplyr across(): Compute column-wise mean
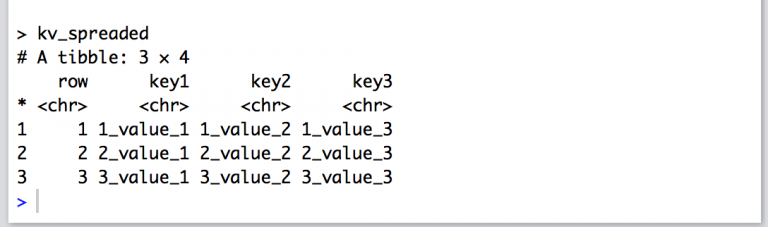
The issue you are running into is because your data is not formatted in a tidy way. all retains all columns from .The first number #_ represents the row (observation) position, the trailing number _# represents the key_ column (variable) position.In R, it’s usually easier to do something for each column than for each row.

Modified 4 years, 5 months ago. Is that really what you want to do? –
Provide details and share your research! But avoid .8? On a related note: Calculating the mean of percentages (proportions) can be dangerous (the mean of a ratio is not the same as the ratio of the means!). The “Tidyverse” is a series of R packages developed primarily by Hadley Wickham and his team at Posit (formerly RStudio). part does de assignment only when .Then I would like to calculate the rowMeans of STUFF and STUFF2 and export the result to a new column. It uses tidy selection (like select()) so you can pick variables by position, name, and type.RData contains a dataframe, prices_xlf, of constituents of the XLF ETF and their daily prices.Using the example data below, my goal is to create a table (publication-ready would be great, but fine if not) where I calculate what percent of each group within each column (city, race, and gender) attend, fail, or both. filter selects rows according to the criteria .There are three possible options for init_cont (A, B, or C) and two possible options for family (D or E), yielding a 3×2 experimental design. The good news is with the gather() function you can get exactly what you need. This is useful for checking your work, as it displays inputs and outputs side-by-side.
How to Replace NAs with column mean or row means with tidyverse
Adding a column of means by group to original data
to create new columns.r – Calculating an average using tidyverse25.I have a working solution but am looking for a cleaner, more readable solution that perhaps takes advantage of some of the newer dplyr window functions. examples of computing row means using rowMeans() and dplyr’s row-wise operations on a dataframe with no missing values. Here’s a solution using the tidyverse.
![How to Get Row Means and Column Means in R. [HD] - YouTube](https://i.ytimg.com/vi/kldnQS5DZ3A/maxresdefault.jpg)
Rolling mean (moving average) by group/id with dplyr
In newer versions of dplyr you can use rowwise() along with c_across to perform row-wise aggregation for functions that do not have specific row-wise variants, but if the row-wise variant exists it should be faster than using rowwise (eg rowSums, rowMeans). Let us find the locations of NAs in the .I’m trying to calculate the weighted mean for multiple columns using dplyr. In this example, we show . So below there is column 201510 repeated 3 times and column 201511 repeated twice.Here is a tidyverse solution using c_across which is designed for row-wise aggregations.
Row-wise operations in R: compute row means in tidyverse
Then I multiple the answer by 100 to get a percent rather than decimal to make the freq column easier to read as a percentage.How is the mean of the vector 0% 10% 0% 70% 20% equal to 0.table with the means by group.(id, operator)] is a small data.When using the programming language R, one consideration is the particular R syntax that will be used. Computing mean of a column of a matrix in R .We want to compute the correlation of the sales from products A, B and C.Schlagwörter:DplyrTidyverse
r
Here is how my dataset looks like: id <- c(1,1,1, 2,2,2, 3,3, 4,4,4) mean <- c(5,5,5, 6,6,6, 7,7, 8,8,8) data <- .Replace NAs with column means in tidyverse. We can apply mean() function to compute mean value of a column of a matrix or a column of a dataframe. mutate(y = all_of(x))), but I .4 it is said: # What proportion of flights are delayed by more than an hour? not_cancelled %>% group_by(year, month, day) %>% . I could accomplish this task using tidyr, but would have to redo a larger number of variables. We can use colMeans() function compute column means. to create new columns . Importing data, computing descriptive statistics, running regressions (or more complex machine learning models) and generating reports are some of the topics covered. No previous experience with R is needed. dplyr at it’s core consists of combining 5 different verbs for data handling: select() . 2017Weitere Ergebnisse anzeigen
Row-wise operations • dplyr
dplyr is one of the packages in the tidyverse, and is focused on manipulating data in data frames.frame and computes the correlation between all the .I’m trying to get used to using tidyverse. We will see multiple examples to compute row means with dplyr.in the R tidyverse chapter 5.I’m not sure how old/new dplyr’s c_across functionality is relative to the prior answers on this page, but here’s a solution that is almost directly cut and pasted from the documentation for dplyr::c_across:.
df %>% rowwise() %>% mutate( mean = mean(c_across(colB:colD)), sd = sd(c_across(colB:colD)) ) # A tibble: 3 x 6 # Rowwise: colA colB colC colD mean sd .rm=TRUE) col_means Nowadays, thanks to the packages from the {tidyverse}, it is very easy and fast to compute descriptive statistics by any stratifying variable(s). The tidyverse works best with long format. Method 1: Calculate Mean by Group Using Base R.I don’t know if my data is well suited for using functions like map().In this tutorial, we will learn how to compute means of rows with tidyverse using dplyr package. The nummos := ifelse.tidyverse in R, one of the Important packages in R, there are a lot of new techniques available maybe users are not aware of. here’s some example code: libr. R column mean by factor. There’s a function for that: tibble::rownames_to_column . Furthermore I could use the R base package, but prefer to find a solution using the mutate function in dplyr.The calculated mean values should be added to the df in an additional column (mean), i.table) dt[ ,list(mean= mean (col_to_aggregate)), by=col_to_group_by] The following examples show how to use each of these methods in practice.I usually have to perform equivalent calculations on a series of variables/columns that can be identified by their suffix (ranging, let’s say from _a to _i) and save the result in new variables/columns.How do you calculate row and column totals for the tibble. The second argument, . A simple way to replace NAs with column means is to use group_by () on the column names and compute means for each column . We will see two examples, first we will compute column-wise mean values when there is no missing values in the dataframe. Add a column with one level factor mean value .We can immediately see that TRUE values considered as ones and FALSE values considered zeros while computing arithmetic mean with mean() function in R. Tidying a data set usually involves .First I modified it to ensure that I don’t get the freq column returned as a scientific notation column by using the scipen option. I’ve read around and looks like I need to use all_of, and maybe across (How to subtract one column from multiple columns in a dataframe in R using dplyr, How to you use objects in dplyr filter?I can get it working for one variable in a mutate phrase (e.fns, is a function or list of . The column names (M1:M3) should not be used directly (in the original dataset, there are many more columns, not just 3). How to group factor levels? 1. You have observations (V1:V3) that are in columns creating a wide data frame.You can use one of the following methods to calculate the mean of a column in R: #calculate mean using column name . In R, we can use many approaches to compute column means.arrange(): Arrange your column data in ascending or descending order; join(): Perform left, right, full, and inner joins in R; mutate(): Create new columns by preserving the existing .
How to Calculate the Mean of a Column in R (With Examples)
The calculations are equivalent, but vary between the variables used in the calculations. 2019dplyr – Rowwise mean on selected columns in R3. And then we will see two examples .
How to Calculate the Mean by Group in R (With Examples)
The following code shows how to use the aggregate() function from base R to calculate the mean points scored by team in the . tidyr is a package from the tidyverse that helps you structure (or re-structure) your data so its easier to visualize and model.cols, selects the columns you want to operate on.
- Geschenkbox Für Zwei : Geschenkboxen günstig online kaufen
- Cuanto Dura El Queso En El Refrigerador
- Events In Singen: Stadtfest : Erfolgreiches Stadtfest 2023
- 5 Free Music Apps That Don’T Need Wi-Fi Or Data
- Unsere Finanzierung Steht: Der Neubau Wird Wirklichkeit
- Bias During The Evaluation Of Animal Studies?
- Wochenhoroskop: 3 Sternzeichen Haben Jetzt Eine Glückssträhne
- Frankreich Besatzungszeit Bilder
- How Fast Hiv Test Results – Understanding Your HIV Test Results
- Facharzt/Fachärztin Für Innere Medizin Und Nephrologie
- Boost Mobile Outage Report • Is The Service Down?
- Abibuch App Kostenlos – abibuch-designer Login
- Bauanleitung Höhlenbrüter-Kasten