K-Means Clustering: Use Cases, Advantages, Working Principle
Di: Jacob
Can warm-start the positions of centroids. These means are then used as the centroid of their cluster: any point that is closest to a given mean is assigned to that mean’s cluster . In such cases, Spectral Clustering helps create more accurate clusters. Some of the use cases of clustering algorithms include: Document Clustering; Recommendation .

Relatively simple to implement. It forms the clusters by minimizing the sum of the distance of points from their respective cluster centroids. Still, in general, they are . For examples of common problems with K-Means and how to address them see Demonstration of k-means assumptions. By selecting a threshold on the x-axis, the data is separated into two clusters.It is one of the most popular clustering methods used in machine learning.Kmeans clustering is one of the most popular clustering algorithms and usually the first thing practitioners apply when solving clustering tasks to get an idea of the structure of .Advantages of k-means.
K-Means Clustering
Here’s how it works: 1. In other words, k-means finds . Download book . To better understand this principle, a classic example of mono-dimensional data is given below on an x axis.
DBSCAN Clustering: How Does It Work?
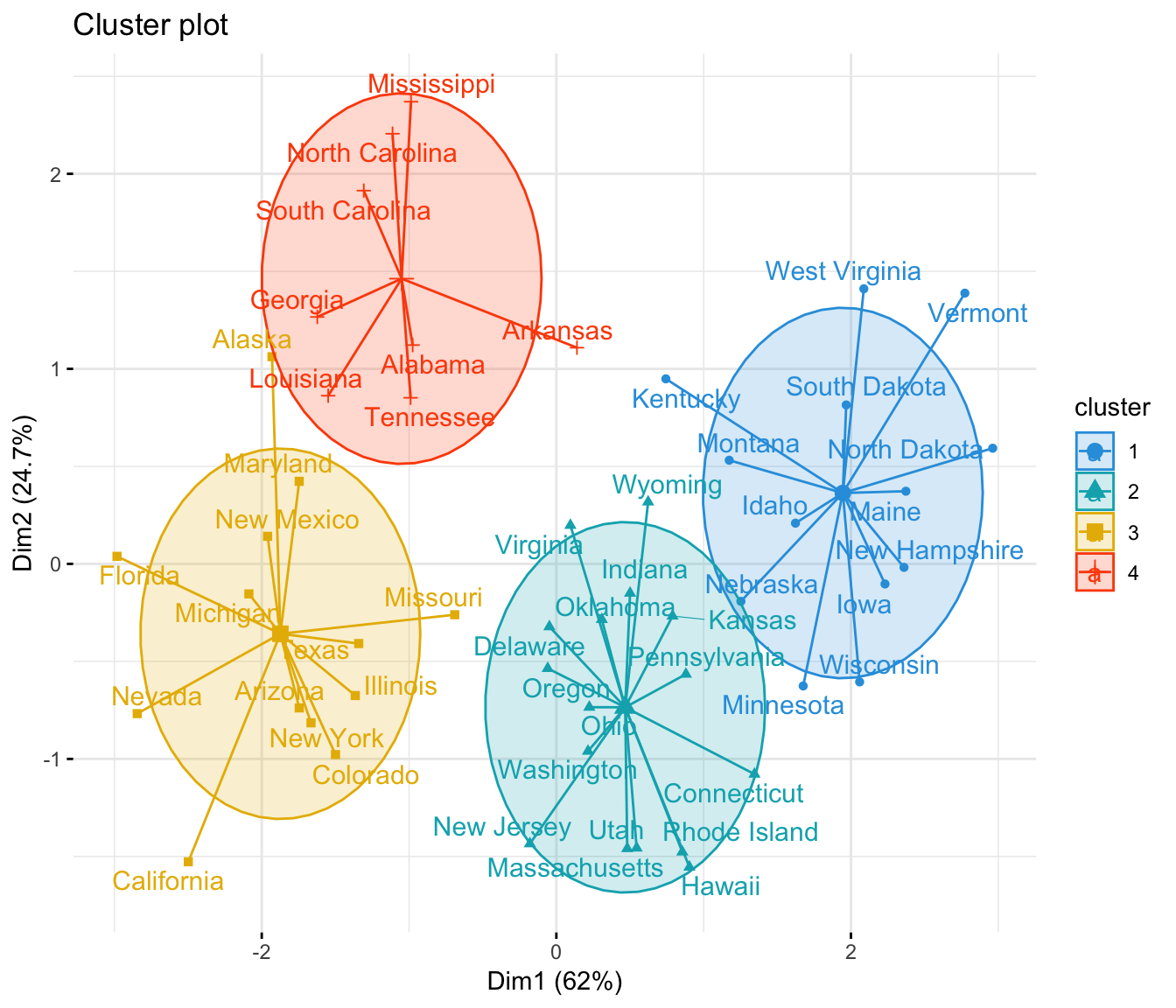
Let’s look at the example below: On this 2D dataset, it becomes clear that it can be divided into 3 groups. The Elbow method.com/Myself Shridhar Mankar an Engineer l YouTube. It can correctly cluster observations that actually belong to the same cluster, but are farther off . Spectral clustering helps us overcome two major problems in clustering: one being the shape of the cluster and the other is determining the cluster centroid.This is an introductory article to K-Means clustering algorithm where we’ve covered what it is, how it works, and how to choose K.Today, we’ll explore two of the most popular clustering algorithms, K-means and hierarchical clustering.First, K-means has some distinct advantages compared with other clustering algorithms.K-means is a widely used clustering algorithm in field of data mining across different disciplines in the past fifty years. The resulting clusters . This article was published as a part of the Data Science . Data within a specific cluster bears a higher degree of . Its ability to group data into clusters. Conference paper. We will use the Silhouette score and Adjusted rand score for evaluating clustering algorithms. Therefore, the k-means clustering algorithm forms tight clusters, .K-Means Clustering is a versatile and powerful machine learning technique widely used for pattern recognition and data analysis.What is KMeans? K-Means divides the dataset into k (a hyper-parameter) clusters using an iterative optimization strategy. A score near 1 denotes the best meaning that the data point i is very compact within the cluster to which it belongs and far away from the other clusters. You have to set the number of clusters – the value of k. This approach allows the algorithm to adapt to different patterns and make predictions based on the local . K-means is a popular partitioning clustering algorithm that is widely used in data mining and machine learning. This algorithm generates K clusters associated with a dataset, it can be done for various scenarios in different industries including pattern detection, medical diagnostic, stock analysis, community detection, market segmentation, image segmentation etc. Divisive clustering uses a top-down approach, wherein all data points start in the same cluster. In the next article, we’ll walk through the process . Easily adapts to . The Elbow method . Then this data is clustered using any traditional technique. Data Science & Business Analytics AI & Machine Learning Project Management Cyber Security Cloud Computing DevOps . K-means clustering works best with data that is on a similar scale, while hierarchical clustering can handle data that is on different scales.
Each cluster is represented by a centre.

Read on to know more! All Courses.K-Means clustering algorithm is defined as an unsupervised learning method having an iterative process in which the dataset are grouped into k number of predefined non-overlapping clusters or subgroups, making the inner points of the cluster as similar as possible while trying to keep the clusters at distinct space it allocates the data points to .Clustering the Data: This process mainly involves clustering the reduced data by using any traditional clustering technique – typically K-Means Clustering. Naturally, knowing the true number of clusters beforehand rarely happens.In a nutshell, K-means is a prototype-based, simple partitional clustering algorithm that attempts to find \(K\) non-overlapping clusters. In this guide, we will first take a look at a simple example to understand how the K-Means algorithm works before implementing it using Scikit-Learn.K-means is a clustering algorithm with many use cases in real world situations.How to perform Cluster Analysis using the K-means technique? How to find the optimal number of clusters? How to identify appropriate features? Why and when do we need to . Gain practical insights into implementing K-means clustering using Python.The K-NN algorithm works by finding the K nearest neighbors to a given data point based on a distance metric, such as Euclidean distance.K-Means clustering uses the Euclidean Distance to find out the distance between points. A point belongs to .K-Means clustering is an unsupervised learning algorithm. This is a strong assumption and may not always be relevant. Disadvantages of K-Means: Applications of K-Means Clustering. Cite this conference paper.Learn the working principles of the K-means algorithm, including centroid computation and iterative optimization. There are some methods to automatically determine the probable number of clusters (the elbow method). Every Machine Learning engineer wants to achieve accurate predictions . K-means clustering is a method of separating data points into several similar groups, or “clusters,” characterized by their midpoints, which we call centroids.There are many different clustering algorithms.
Understanding K-Means Clustering Algorithm
These clusters are then joined greedily, by taking the two most similar clusters together and merging them. Two hyperparameters must be determined by the user in implementing k-means clustering: the number of centroids k, and the distance metric used (usually Euclidean distance or Manhattan distance).Evaluation Metrics For DBSCAN Algorithm In Machine Learning .The K-Means Clustering algorithm works with a few simple steps.K-Means clustering is one of the most powerful clustering algorithms in the Data Science and Machine Learning world. For each cluster, you further divide .Centroid update: move centroids to the means of observations of the same cluster.Schlagwörter:K-Means ClusteringK-means Algorithms This is because hierarchical clustering uses a distance-based approach, which can handle data with . Learn to understand the types of clustering, its applications, how does it work and demo.Clustering techniques, like K-Means, assume that the points assigned to a cluster are spherical about the cluster centre. How do we go about it? The idea is quite simple and .In a sense, K-means considers every point in the dataset and uses that information to evolve the clustering over a series of iterations.
K-Nearest Neighbor(KNN) Algorithm
Schlagwörter:Machine LearningClustering AlgorithmK-Means Clustering Unsupervised The algorithm successively minimizes the sum of distances between the data points and their respective cluster centroids. In this story, we .K-means plays a vital role in data mining and is the simplest and most widely used algorithm under the Euclidean Minimum Sum-of-Squares Clustering (MSSC) model.K-means clustering is an unsupervised machine learning technique that sorts similar data into groups, or clusters. That is, K-means is very simple and robust, highly efficient, and can be used for a wide variety of data types. What is K-means Clustering? K-means clustering is an unsupervised machine learning approach that uses similarities to divide a . Clustering vs Classification. Unlike hierarchical clustering, K-means is a centroid-based algorithm that assigns each data point to the nearest cluster centroid. Given a set of points and an integer k, the algorithm aims to divide the points into k groups, called clusters, that are homogeneous and compact. Before starting our discussion on k-means clustering, I would like point out the difference between clustering and classification.K-Means Clustering is an unsupervised learning algorithm that aims to group the observations in a given dataset into clusters.Clustering helps marketers improve their customer base, work on target areas, and segment customers based on purchase history, interests, or activity monitoring. In this post, I will cover one of most common clustering algorithms: K-Means Clustering. Ask user how many clusters they’d like.Another difference between hierarchical clustering and K-means clustering is the scale of the data. Randomly guess k cluster Center locations 3. Scales to large data sets. Indeed, it has been ranked the second among the top-10 data mining algorithms in , and has become the defacto benchmark method for newly proposed .
A Practical Guide on K-Means Clustering
There are several research works reporting on robust K .Fuzzy clustering (also referred to as soft clustering or soft k-means) . K-means works by selecting k central points, or means, hence K-Means.In this blog, we will explore the use cases, advantages, and working principles of the K-means clustering algorithm. Familiarize oneself with real-world examples and applications of K-means clustering in various domains. And because clustering is a very important step for understanding a dataset, in this article we are going to discuss what is clustering, why do we need it and what is k-means clustering going . This data set can be traditionally grouped into two clusters.
Definitive Guide to K-Means Clustering with Scikit-Learn
K-means algorithm generally assumes that the clusters are spherical or round i. within k-radius from the cluster centroid. These clusters are represented by their . AI & Machine Learning.Silhouette’s score is in the range of -1 to 1. For a demonstration .For a more detailed example of K-Means using the iris dataset see K-means Clustering.K-means is an iterative, centroid-based clustering algorithm that partitions a dataset into similar groups based on the distance between their centroids.There are various clustering algorithms with K-Means and Hierarchical being the most used ones. Samples in a classification task have labels .The benefits of the k-means algorithm are that it is easy to implement, it scales to large datasets, it will always converge, and it fits clusters with varying shapes and sizes. Unlike supervised learning, the training data that this algorithm uses is unlabeled, meaning that data points do not have a defined classification structure. K-Means Clustering. Guarantees convergence. First, each node is assigned a row of the normalized of the Graph Laplacian Matrix.Pros and Cons of Spectral Clustering.
k-means clustering
When to Use Hierarchical Clustering: A Guide for Data Analysts
The centroid, or cluster .
k-Means Advantages and Disadvantages
Robust K-means algorithms focus on resolving the adverse effects of outliers on K-means clustering.K-means advantages K-means drawbacks; It is straightforward to understand and apply.K-means is an unsupervised clustering algorithm designed to partition unlabelled data into a certain number (thats the “ K”) of distinct groupings. Each datapoint finds out which Center it’s closest to. While various types of clustering algorithms exist, including exclusive, overlapping, hierarchical and probabilistic, the k .The Principle of the K-means Algorithm.
K-Means Clustering: Use Cases, Advantages and Working Principle
Initializing k-Means Efficiently: Benefits for Exploratory Cluster Analysis. To transform the clustering result, the node identifier is .
K-Means Clustering Explained
Shuffle the data and randomly assign each data point to one of the K clusters .k-means clustering is a method of vector quantization, originally from signal processing, that aims to partition n observations into k clusters in which each observation belongs to . Repeat steps 2 and 3 until convergence is reached. You can then use a parametric clustering algorithm like K-Means to divide the cluster into two clusters. It is applicable to clusters of different shapes and dimensions.

K-Means Clustering is an algorithm that takes one hyperparameter (the number of clusters) and generates the centroids of those clusters. Note: An example of K-Means clustering is explained with customer segmentation examples in the use cases section below. There are two methods to choose the correct value of K: Elbow and Silhouette. For an example of how to use K-Means to perform color quantization see Color Quantization using K-Means.It is very simple, yet it delivers wonderful results. Contents Basic Overview Introduction to K-Means .K-means clustering operates on the principle of minimization of within-cluster variance, often referred to as the inertia or within-cluster sum of squares criterion. The number of clusters is provided as an .“K-means clustering is a method of vector quantization, originally from signal processing, that aims to partition n observations into k clusters in which each observation belongs to . K-Means clustering is one of the most widely used unsupervised machine learning algorithms that form clusters of data based on the similarity between data instances.K-Means Clustering. The number of clusters is provided as an input. First Online: 11 October 2019.Data Science Noob to Pro Max Batch 3 & Data Analytics Noob to Pro Max Batch 1 ? https://5minutesengineering. However, k-means heavily depends on. In K-means, the algorithm requires . It is a fast and efficient algorithm that works well with large datasets. Assign the K number of clusters. The class or value of the data point is then determined by the majority vote or average of the K neighbors.
- Indonesische Zeichen Übersetzer
- Dr. Heiko Armin Schreiber : Klinik und Poliklinik für Allgemeine Chirurgie: Schreiber
- Welche Schlittschuhe? _ Schlittschuh: Test & Vergleich (05/2024) der besten Schlittschuhe
- Bauknecht Schweiz : Dunstabzugshauben: Inselhaube, integriert oder Wandmontage
- Prénom Albert : Signification, Origine, Saint, Avis
- Sicherheit Auf Fahrtreppen : Schindler Fahrtreppen und Fahrsteige
- 15 Best Sheep Breeds For Wool! [Fine Clothing, Socks, And Sweaters!]
- Quais São As Principais Células Do Tecido Ósseo?
- Unlock Thrift Shop Outfits _ Thrift Store Overhaul
- Grace: Serienstart Bei Itv , Der Fall Natalia Grace
- Can’T Access Shared Folder Of Win8/Win7 Machine
- Allgemeine Regeln Im Schiessen