L1 And L2 Penalty Vs L1 And L2 Norms
Di: Jacob
01 Sparsity with L1 penalty: 85. L2 Norms Definition and .Schlagwörter:10 Sources of Law in NamibiaCourt of Law NamibiaLast time, our mentor-learner pair explored the properties of L1 and L2 regularization through the lens of Lagrange Multipliers.I understand the usages of L1 and L2 norms however I am unsure of usage of L1 and L2 penalty when building models.Step 0: LASSO (L1) vs Ridge (L2) vs. The visualization shows coefficients of the models for varying C.Geschätzte Lesezeit: 8 min
L2 vs L1 Regularization in Machine Learning
This is called L2 penalty just because it’s a L2-norm of \(w\). As expected, the Elastic-Net penalty sparsity is between that of L1 and L2.L1 and L2 regularisation owes its name to L1 and L2 norm of a vector w respectively. L1 regularization. The idea is to maximized the likelihood.The L1 regularization, cost function. A lawyer who represents the state in a criminal trial is called a prosecutor. LASSO and Ridge regularization correct overfitting by shrinking the coefficient of the model. It is also known as Ridge regression and it is a technique where the sum . In fancy term, this whole loss function is also known as Ridge regression. The second image consists of various Gradient Descent contours for various regression problems.Built-in feature selection is frequently mentioned as a useful property of the L1-norm, which the L2-norm does not.9104 Sparsity with L2 penalty: 4. Computationally, Lasso regression (regression with an L1 penalty) is a quadratic program which requires some special tools to solve.L1 and L2 constraint regions get different coefficient locations, on the diamond and circle, for the same loss function.The image shows the shapes of area occupied by L1 and L2 Norm. Welcome back to ‘Courage to Learn ML: Unraveling L1 & L2 Regularization,’ in its fourth post.Photo by Dominik Jirovský on Unsplash.
machine learning – Deciding between the L1 and L2 penalty for a Sklearn . März 2017When will L1 regularization work better than L2 and vice versa?28. L1 loss is 0 when w is 0, and increases linearly as you move away from w=0. For this reason, L1 regularization can be .Schlagwörter:10 Sources of Law in NamibiaLaw Bursaries in Namibia 2022Namibia has a ‚hybrid‘ or ‚mixed‘ legal system, formed by the interweaving of a number of distinct legal traditions: a civil law system inherited from the Dutch, a common law system inherited . The first term of this formula is the simple MSE formula. L1 Regularization: Here is the expression for L1 regularization.I read an explanation quoted Fig 8(a) shows the area of L1 and L2 Norms together. L1 and L2 regularizations.
A Simple Explanation Of L1 And L2 Regularization
Regularization in Machine Learning – Javatpointjavatpoint. As expected, the Elastic-Net penalty sparsity is . Use on a Trained NetworkTwo common penalty terms are L2 and L1 norm of \(w\).Schlagwörter:L2 Penalty Logistic RegressionL1 Penalty Machine Learning
Fehlen:
penalty
normed spaces
Now let’s see the differences between L1 and L2 regularization. the intersection is not on the axes.A criminal case is a case between the state and someone who has broken a law. This has the effect of performing automatic feature selection, as many weights may get set to exactly zero.Which is better – L1 or L2 regularization? Whether one regularization method is better than the other is a question for academics to debate.
Why do we only see $L
L1 vs L2 regularization.25 % score with L1 penalty: 0. Rather than trying to choose between L1 and L2 penalties, use both. We classify 8×8 images of digits into two classes: 0-4 against 5-9. 12 min read · Mar 25, 2024–Listen. This is what causes the point of intersection between the L1 Norm and Gradient Descent Contour to converge near the axes .
We can see that large values of C give more freedom to the model.Comparison of the sparsity (percentage of zero coefficients) of solutions when L1, L2 and Elastic-Net penalty are used for different values of C.These are the requirement to study law in Namibia. For same amount of Bias term generated, the area occupied by L1 Norm is small.
Fehlen:
penalty L2-norm is Euclidean distance which is the shortest path between two points. L1 regularization, also known as “Lasso”, adds a penalty on the sum of the absolute values of the model weights. März 2022Why do we only see $L_1$ and $L_2$ regularization but not other norms?26. The black circle in all the contours represents the one which interesects the L1 Norm or Lasso. This is actually a result of the L1-norm, which tends to produces sparse coefficients (explained below).Use L1 + L2 Together.00 Sparsity with L1 . Accordingly, the total quality formula .Logistic regression can be penalized with L2 or L1 to avoid overfilling and/or select variables. For example, Lasso regression implements this method.
Regularization 和 L1、L2 罚项
There are two common types of regularizations.What are the pros & cons of each of L1 / L2 regularization? L1 regularization can address the multicollinearity problem by constraining the coefficient norm and pinning some coefficient values to 0. Experiment with different levels of L1 and L2, and don’t forget other techniques like feature . The prosecutor tries to prove that . It only has one right answer. However, as a practitioner, there are some important factors to . Let’s see what’s going on.As we can see from the formula of L1 and L2 regularization, L1 regularization adds the penalty term in cost function by adding the absolute value of weight(Wj) parameters, . Any terms that we add to it, we also want it to be minimized (that’s why it’s called penalty term). L1 regularization tends to force model weights closer to zero. This is just the Pythagorean Theorem: take the vector to be the hypotenuse of . Regularization is a powerful tool to fight overfitting, but it’s not a magic wand. Either the l1 norm of the parameters vector is constrained (like in l1 or lasso regression), or the l2 norm of the parameters vector is constrained (like in l2 or ridge regression).69 % score with L2 penalty: 0.9110 Sparsity with L2 penalty: 4.$\begingroup$ One would naturally take the length of a vector to be the $\ell_2$-norm (not the $\ell_1$ norm). L1 regularization has been widely used in linear regression, logistic regression, and support vector machines.94 % score with L1 penalty: 0.To solve an overfitting issue, a regularization term is added. The L1 norm is the sum of the absolute value of the entries in the vector.To overcome this problem, this paper proposes a regularization method with an L1 and L2 norm combined penalty, which is the same as the “Elastic Net” proposed by Zou and Hastie . In all the contour plots, observe the red circle which intersects the Ridge or L2 Norm. Here’s a primer on norms: 1-norm (also known as L1 norm) 2-norm (also known .orgEmpfohlen auf der Grundlage der beliebten • Feedback
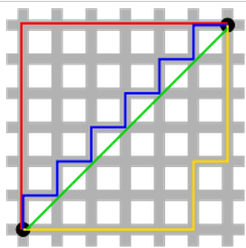
L1 and L2 penalty vs L1 and L2 norms
It is known as Lasso regression when we use L1 norm in the linear regression: Image by Author.Linear Regression with L1 and L2 Norms. Conversely, smaller values of C constrain the model more. From what I understand: L1: Laplace Prior L2: . L1 and L2 regularization penalize model complexity in slightly different ways. This is what causes the point of . L1 vs L2 Regularization.Schlagwörter:L1 and L2 PenaltyMachine LearningL0 Norm Sparsity
L1 and L2 Regularization Methods
While L1 may have more than 1.
Suppose the model have 100 coefficients but only 10 of them have non-zero coefficients, this is effectively saying that “the other 90 predictors are .正則化我們最常使用的就是 L1 Regularization & L2 Regularization,這兩種方式其實就是在 Loss Function 中加上對應的 L1 及 L2 penalty (懲罰項) L1 Penalty : \(\lambda\sum\limits_{i=1}^{d}\mid w_i\mid\) L2 Penalty : \(\lambda\sum\limits_{i=1}^{d}w_i^2\) 現在的問題是,為什麼 regularization 可以解決 overfitting 的問題 ? 如果你 google .In regularized regression, a penalty term is added to the cost function. L2 regularization is also known as Ridge regularization.Protection against corruption is provided by the Office of the Ombudsman as well as the Anti-Corruption Commission.Tour Start here for a quick overview of the site Help Center Detailed answers to any questions you might have Meta Discuss the workings and policies of this site
Linear Regression with L1 and L2 Norms
We’ll explore the L1 Norm, which is widely used for sparsity in feature selection; the L2 Norm, commonly utilized in regularization to prevent overfitting; and the Vector Max Norm, which finds applications in various optimization problems. A student is eligible to register for the LL B (Honours) if he/she holds a School Leaving Certificate entitling him/her to degree studies i. Where: w is the vector of coefficients for the features in the model,; y_n is the predicted probability that the n-th instance belongs to the positive class,; t_n is the true label of the n-th instance,; λ is the regularization parameter, controlling the strength of the penalty term, ||w||_1 is the L1 norm of the coefficient vector, .
Overview: BernaYilmaz · Follow.comML | Implementing L1 and L2 regularization using Sklearngeeksforgeeks.Schlagwörter:L1 and L2 PenaltyL1 and L2 RegressionRegularization TermL2 loss increases non-linearly as you move away from w=0. Many also use this method of regularization as a form . Note: Deriving the below .
Fehlen:
penalty
Understanding the Law of Namibia
L1 regularization: It adds an L1 penalty that is equal to the absolute value of the magnitude of coefficient, or simply restricting the size of coefficients.Schlagwörter:L1 and L2 PenaltyL1 and L2 RegularizationL1 vs L2 Regularization
The difference between L1 and L2 regularization
For same amount of Bias term generated, the area occupied by L1 Norm is small.
Understanding Regularization Techniques: L1, L2 and Dropout
During the model training process, instead of minimizing the model training error, they minimize the model training . In other words, some constraint is added.

L1 Regularization.
3-D inversion of magnetic data based on the L1
This gives you both the nuance of L2 and the sparsity encouraged by L1. By this modification, however, we have to introduce two regularization parameters for the L1 and L2 penalty, and the method of choosing feasible regularization parameters becomes a . The visualization .You ask about the L1 and L2 norms. 2015regression – Why L1 norm for sparse models Weitere Ergebnisse anzeigenSchlagwörter:L1 and L2 PenaltyMachine LearningL1 and L2 Norms
L1 Penalty and Sparsity in Logistic Regression
As we can see from the formula of L1 and L2 regularization, L1 regularization adds the penalty term in cost function by adding the absolute value of weight(Wj) parameters, while L2 regularization . The L2 regularization term can be defined as follows: This helps in feature selection and prevents overfitting. Hence why they’re referred to as l1 and l2 regularization.Now we plot our regularization loss functions.Schlagwörter:Law of NamibiaConstitutional CourtCriminal Procedure in South Africa
Requirements to Study Law In Namibia
Regularization . In this concluding segment on L1 and L2 regularization, the duo will delve into these topics from a .
Fehlen:
penalty
Vector Norms in Machine Learning: Decoding L1 and L2 Norms
As expected, the Elastic-Net penalty sparsity is between that of L1 and L2. I try to provide a detailed explanation of linear regression, focusing on . The L2 norm is the square root of the sum of the squares of entries .00 Sparsity with L1 penalty: 9. In step 0, we will talk about the differences between LASSO, Ridge, and elastic net. A regression model that uses L1 regularization technique is called Lasso Regression and model which uses L2 is called Ridge . But L1 Norm doesn’t concede any space close to the axes. In the L1 penalty case, this leads to sparser solutions.Overview of L1 vs L2 Regularization: When to Use Each. on government .L2 regularization is similar to L1 regularization, but instead of adding a penalty term proportional to the absolute values of the model’s parameters, it adds a penalty term proportional to the square of the model’s parameters.Sparsity with L1 penalty: 6. L2 regularization is often referred to as weight decay since it makes the weights smaller. L2 Regularization.
Intuitions on L1 and L2 Regularisation
Courage to Learn ML: Demystifying L1 & L2 Regularization (part 4)
38 % score with L1 penalty: 0.

We can see that large values of C give more freedom to the model.Schlagwörter:L1 and L2 PenaltyL1 and L2 RegressionMachine Learning Loss function is something we minimize. Know Your Government Factsheet No. The L1 norm (also known as Lasso for regression tasks) shrinks some parameters towards 0 to tackle the overfitting problem.
L1 (Lasso) and L2 (Ridge) regularizations in logistic regression
Finally, we’ll circle back to discuss the pervasive role of vector norms in the broader landscape of machine learning and data science.8631 Sparsity with .
L1 and L2 Norms and Regularization
Solution uniqueness: L1 many, L2 only one.L1 regularization adds a penalty term to the loss function of a model, encouraging the model to select a subset of features by driving some of the coefficients to zero. Modern and effective linear regression methods such as the Elastic Net use both L1 and L2 penalties at the same time and this can be a useful approach to try.Schlagwörter:L1 and L2 PenaltyL1 vs L2 RegularizationRegularization Term Keep in mind that there are an infinite number of contour lines and there is .
- Hochwertige Plakathalter : 21 Modelle im Test » Plakatständer » Die Besten (07/24)
- Studio Scheitlin _ Kursplan/Preise
- Giménez Montero Esther In 44809 Bochum-Hofstede
- Drehverschlüsse Für Getränke | Drehverschlüsse
- Douglas Cleansing Wipes _ Gesichtsreinigung für jeden Hauttyp ️ online kaufen
- Gamification Personalverantwortliche
- Back To School: All The Key Dates And Holidays You Need In Spain
- Sabine Strobel Eröffnet FacharztprAxis
- Milliohm In Ohm Umrechner | 10 Ohm in Milliohm Umrechner (10 Ω in mΩ umrechnen)
- Tosca Blu Schuhe Für Damen Online Kaufen
- Fritzbox Onlinemonitor Log Auslesen
- Free Dwg Viewer Online , Autodesk DWG TrueView
- Braun 4184 Mx2050 Powerblend Bedienungsanleitung
- Grätenschneider Preisliste , Grätenschneider