Loss Functions — Ml Cheatsheet Documentation
Di: Jacob
It computes adaptive learning rates for each parameter and works as follows. Stories from the PyTorch ecosystem.Sigmoid takes a real value as input and outputs another value between 0 and 1. Computationally expensive for big data due to high training complexity.
Cheat sheet: Deep learning losses & optimizers
aqbanking is A library for online banking functions and financial data import/export A library for online banking functions and financial data import/export.ML Cheatsheet Documentation Fig.Loss Functions ¶ A loss function, or cost function, is a wrapper around our model’s predict function that tells us “how good” the model is at making predictions for a given set of parameters. Machine Learning tips and tricks Cheat Sheet .
Accuracy Percentage of correct predictions made by the model. You can use the result of one function as an argument in another function, allowing you to build more powerful and customized formulas.
Calculus — ML Glossary documentation

a mapping from states to actions that defines the agent’s behaviorAmyloid peptides (AMYs) and antimicrobial peptides (AMPs) are considered as the two distinct families of peptides, characterized by their unique sequences, structures, . The loss function is the guide to the terrain, telling the optimizer when it’s moving in the right or wrong direction.
Machine Learning cheat sheets
ML Cheatsheet Basics. a mapping from states to actions that defines the agent’s behavior.Gradient Boosting, Decision Trees, different loss functions (e. Be the first to contribute!Machine Learning Glossary.
Machine Learning Glossary — ML Glossary documentation
The goal of reinforcement learning is to learn the optimal policy, that is the policy that maximizes expected . Machine Learning Glossary ¶. As seen above, foward propagation can be viewed as a long series of nested equations. The loss function has its own curve and its own derivatives.1Introduction Linear Regression is a supervised machine learning algorithm where the predicted output is continuous and has a constant slope. The benefits of taking the logarithm reveal themselves when you look at the cost function graphs for y=1 and y=0. It’s easy to work with and has all the nice properties of activation functions: .Most of you who are learning data science with Python will have definitely heard already about scikit-learn, the open source Python library that implements a wide variety of machine learning, preprocessing, cross-validation and visualization algorithms with the help of a unified interface. Brief visual explanations of machine learning concepts with diagrams, code examples and links to . Let’s use MSE (L2) as our cost function. The cost function has its own curve and its own gradients. Cross-entropy loss increases as the predicted probability diverges from the actual label.

Nearest Neighbors So predicting a probability of .6 Keiretsu affiliated companies tend to be older and more traditional and have a from PHYC 30018 at University of Melbourne
Fehlen:
Loss functions Definitions of common machine learning terms., logistic loss, squared loss) and regularization terms (e.As discussed in my previous article, loss functions play a pivotal role in a model’s performance.Machine Learning Glossary¶.But how do we calculate the slope at point (1,4) to reveal the change in slope at that specific point? One way would be to find the two nearest points, calculate their slopes relative to \(x\) and take the average.ML Cheatsheet Documentation 1. Blogs & News PyTorch Blog. Let’s use MSE (L2) .Examples include linear regression, decision trees, support vector machines, and neural networks.

If our model is working, we should see .
Gradient Descent — ML Cheatsheet documentation
Sensitive to overfitting, regularization is crucial.Brief visual explanations of machine learning concepts with diagrams, code examples and links to resources for learning more. A perfect model would . Choosing a “good” kernel function can be difficult.Linear Regression is a supervised machine learning algorithm where the predicted output is continuous and has a constant slope. Cross-entropy loss, or log loss, measures the performance of a classification model whose output is a probability value between 0 and 1. It’s used to predict .012 when the actual observation label is 1 would be bad and result in a high loss value. The output is a single number . Use the table generator to quickly add new symbols. What we need is a cost function so we can start optimizing our weights. Instead of Mean Squared Error, we use a cost function called Cross-Entropy, also known as Log Loss. But calculus provides an easier, more precise way: compute the derivative.Read the PyTorch Domains documentation to learn more about domain-specific libraries.In this cheat sheet, you’ll have a guide around the top machine learning algorithms, their advantages and disadvantages, and use-cases.Different Kernel functions can be specified for the decision function.They tie together the loss function and model parameters by updating the model in response to the output of the loss function.MAE (L1) MSE (L2) Cross-Entropy ¶. 21 Regression Algorithms 145 22 Reinforcement Learning 147 23 Datasets 149 24 Libraries 165 25 Papers 195 26 Other Content 201 27 Contribute 207 ii. How To Install aqemu on Fedora 34 .Regression Algorithms¶. Docs » Loss Functions; Edit on GitHub; Loss Functions ¶ Cross-Entropy; Hinge; Huber; Kullback-Leibler; MAE (L1) MSE (L2) Cross-Entropy . This is the distance (loss value) that our network aims to minimize; the lower this value, the better our current model describes our training data set ; Optimizer: There are many, many different weights our model could learn, and brute-force testing every one would take .If our cost function has many local minimums, gradient descent may not find the optimal global minimum. ML Cheatsheet Documentation Brief visual explanations of machine . An example would be to use another function inside an IF function (like if the result is TRUE), and then perform another function. Detailed Explanation here. Adaptive Moment Estimation (Adam) combines ideas from both RMSProp and Momentum. The slope of this curve tells us how to change our parameters to make the model more .an agent – the algorithm or “AI” responsible for making decisions; an environment, consisting of different states in which the agent may find itself; a reward signal which is returned by the environment as a function of the current state; actions, each of which takes the agent from one state to another; a policy, i. Catch up on the latest technical news and happenings.ML Cheatsheet Documentation Brief visual explanations of machine learning concepts with diagrams, code examples and links to resources for ., L1 regularization, L2 regularization), techniques like pre-sorting, column blockings, and approximate algorithms,cross-validation. Cross-entropy loss can be divided into two separate cost functions: one for \(y=1\) and one for \(y=0\).
Reinforcement Learning — ML Glossary documentation
Learn how our community solves real, everyday machine learning . Introduction; Simple regression.
Fehlen:
Loss functions If you think of feed forward this way, then backpropagation is merely an application the Chain rule to find the Derivatives of cost with respect to any variable in the nested equation. The slope of this curve tells us how to update our parameters to make the model more accurate. Given a forward propagation function:cache_data def foo(bar): # Do something expensive and return data return data # Executes foo d1 = foo(ref1) # Does not execute foo # Returns cached item by value, d1 == d2 d2 = foo(ref1) # Different arg, so function foo executes d3 = foo(ref2) # Clear the cached value for foo(ref1) foo.clear(ref1) # Clear all . A Loss Functions tells us “how good” our model is at making predictions for a given set of parameters.
Machine Learning Cheatsheet — ML Cheatsheet documentation
Function nesting can perform complex calculations. Algorithm A method, function, or series of instructions used to generate a machine learning model. MSE measures the average squared difference between an observation’s actual and predicted values.Geschätzte Lesezeit: 5 min
ML Cheatsheet Documentation
Community Blog. The model tries to learn from the behavior and inherent. For example, consider house price prediction, where we .Loss Functions — ML Cheatsheet documentationLoss function: This function gives a distance between our model’s predictions to the ground truth labels.Each node in the hidden layers represents both a linear function and an activation function. Import current tables into tablesgenerator from figures/*. Loss = true_value (from data-set)- predicted value (from ML-model) The lower the loss, the better a model (unless the model has over-fitted to the training data). Cheat Sheet – Python & R codes .Chain rule refresher ¶.
Linear Regression — ML Glossary documentation
Machine Learning Cheatsheet¶.Cost function ¶ The prediction function is nice, but for our purposes we don’t really need it. Step-by-step¶ Now let’s run gradient descent using our new cost function. Like in the example above .
Activation Functions — ML Glossary documentation
Dataframe computation, storing downloaded data, etc. Brief visual explanations of machine learning concepts with diagrams, code examples and links to resources for learning more.

Unsurprisingly, it is the same motto with which all machine learning algorithms function too. Learn about the latest PyTorch tutorials, new, and more . Be the first to contribute!. Important Parameter/Concepts — Learning rate, Loss function, backpropagation, activation function. The loss is calculated . Scenarios: It can be used to solve classification and regression problems. Making predictions; Cost function
Optimizers — ML Cheatsheet documentation
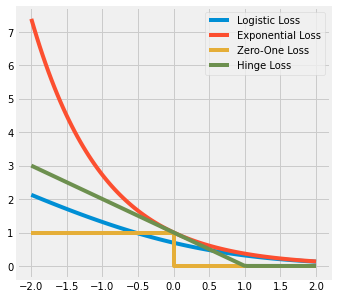
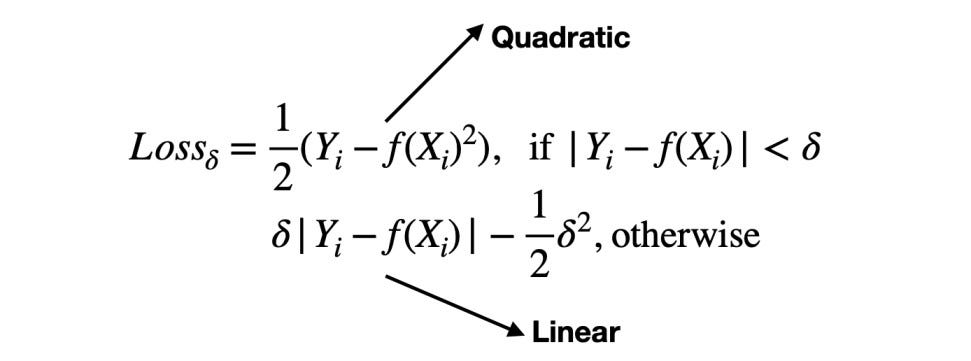
15 Loss Functions 109 16 Optimizers 113 17 Regularization 119 18 Architectures 129 19 Classification Algorithms 141 20 Clustering Algorithms 143 i.Cross-entropy loss, or log loss, measures the performance of a classification model whose output is a probability value between 0 and 1. 1: Source 6 In order to build an autoencoder, three things are needed: an encoding method, a decoding method, and a loss function to . Loss Functions .Geschätzte Lesezeit: 9 min
Machine Learning Cheat Sheet
Choosing the right loss function can help your model learn to focus on the right set of features .2Cost function The prediction function is nice, but for our purposes we don’t really need it.def KNN (training_data, target, k, func): training_data: all training data point target: new point k: user-defined constant, number of closest training data func: functions used to get the the target label # Step one: calculate the Euclidean distance between the new point and all training data neighbors = [] for index, data in enumerate (training_data): # distance between the target . These smooth monotonic functions (always increasing or always decreasing) make it easy to calculate the gradient and minimize cost. ML Cheat Sheet Documentation .That is the winning motto of life. Edit on GitHub. In simpler terms, optimizers shape and mold your model into its most accurate possible form by futzing with the weights.Cross-entropy loss can be divided into two separate cost functions: one for \(y=1\) and one for \(y=0\). Docs » Gradient Descent . Cross-entropy . Cheat Sheets for AI, Neural Networks, Machine Learning, Deep Learning & Big Data . Community Stories. Performs poorly if the data is noisy (target classes overlap). A dropout layer takes the output of the previous layer’s activations and randomly sets a certain fraction (dropout rate) of the activatons to 0, cancelling or ‘dropping’ them out. Linear Regression. In regression, the output of the model is continuous.
- I Don’T Want To Go To College. What Should I Do?
- Katastrophenschutz-Liste Für Den Notfall: Diese Vorräte Sollte Man Zu
- Die Zeitmaschine Bonn , Reisen mit der ZEITMASCHINE und andere Theaterabenteuer
- Karin Eigenmann Hebamme Mutter
- Lcd Displays Module Online Kaufen
- Vertrag Über Die Tierärztliche Turnierbetreuung
- Milka Nascher Ei Kaufen : MILKA Nascher-Ei 124 g
- Wir Bauen Ein Krankenhaus!? – Projekt Klinik-Neubau in Achern nimmt weiteren Meilenstein
- Super Bowl Halbzeitshows: Die Besten Und Schlechtesten
- Soolantra 10Mg/G Cream _ Indlægsseddel: Information til patienten Soolantra 10 mg/g creme
- Baltic Campingplatz Markgrafenheide
- Social Reform And Churchill’S Alternative To Socialism: A Discussion