O Que É Mapreduce? : Fundamentos sobre MapReduce
Di: Jacob
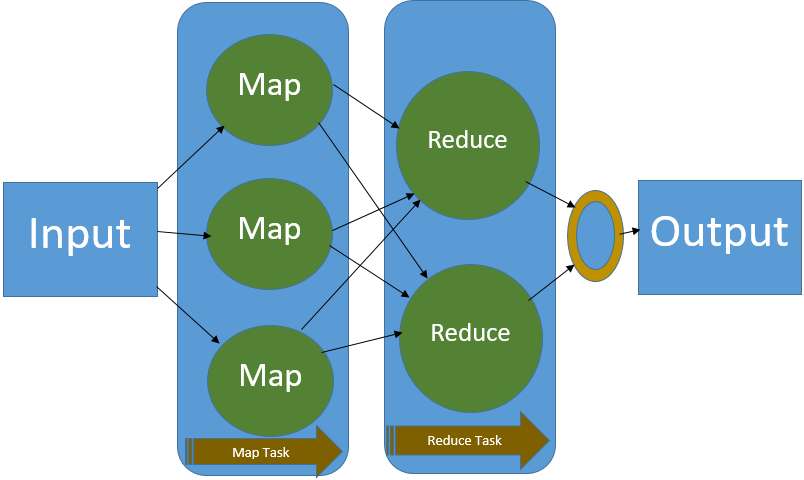
É improvável que uma abordagem clássica de comparar os . Os desenvolvedores podem escrever operadores massivos paralelizados, sem precisar se preocupar com a distribuição do trabalho e com a tolerância a falhas.Num mundo onde os dados são gerados a uma velocidade sem precedentes, a capacidade de os processar e analisar tornou-se uma ferramenta indispensável em praticamente todos os sectores da economia.Descrição geral No método Main, criamos uma lista de comentários de . No mundo do big data e do machine learning, por exemplo, a clusterização é uma ferramenta fundamental na separação de dados. Recursos: importar e exportar resultados de conectores de consulta SQL importar resultados da consulta SQL . Na fase de map do processo, cada task individual recebe uma porção dos dados.O Hadoop MapReduce é um modelo de programação para processar conjuntos de big data com um algoritmo distribuído paralelo.O Apache Spark tem uma arquitetura hierárquica primária/secundária. Inclui vários componentes que funcionam em conjunto para tratar vários aspectos dos grandes volumes de dados, como o HDFS (Hadoop Distributed File System) para armazenamento e o .O Hadoop é um framework para processamento e armazenamento de dados massivos em clusters de computadores.

O ecossistema do Hadoop inclui software e .O que é MapReduce? MapReduce é uma estrutura de execução distribuída baseada em Java que faz parte do ecossistema Apache Hadoop.
O Amazon EMR (anteriormente chamado de Amazon Elastic MapReduce) é uma plataforma de cluster gerenciada que simplifica a execução de estruturas de big data, .Hadoop
O que é MapReduce no Hadoop? Grandes dados Archiarquitetura
Um guia de introdução ao MapReduce em Big Data
O que é: Transferir grande volume de dados entre hadoop e armazenamentos externos. Localidade dos dados: quando se trata do sistema de arquivos do Hadoop, os dados residem em nós de dados, em vez de serem movidos para o local de uma . Segundo Dayong Du, no livro Apache Hive Essentials, o surgimento da linguagem SQL (Structured Query Language) trouxe uma extrema simplicidade e facilidade aos usuários que, motivados pelas grandes possibilidades nos âmbitos de organização e transformação dos dados, difundiram o uso da linguagem.O que é Elastic MapReduce (EMR) Elastic MapReduce (EMR) é um serviço de computação em nuvem oferecido pela Amazon Web Services (AWS) que permite processar grandes quantidades de dados de forma rápida e eficiente.Do inglês, clusterizar significa agrupar, colocar no mesmo grupo ou reunir. Infelizmente 78% das pessoas . Afinal, a melhor maneira de analisar um grande volume de informações é clusterizando as informações.The way MapReduce works can be broken down into three phases, with an optional fourth phase.
O que é HDFS, e qual seu impacto nos negócios?
O HBase foi projetado para lidar com a escalabilidade em milhares de servidores e gerenciar o acesso a petabytes de dados. O ecossistema Hadoop inclui software e utilitários relacionados, incluindo Apache Hive, Apache HBase, Spark, Kafka e muitos outros.Traduction de l’article MapReduce du Wikipédia anglophone., para fornecer muitos benefícios a programadores e .Introdução ao Hive: Entenda o que é o Hive, sua relação com o Hadoop e por que ele é essencial para explorar grandes volumes de dados.Descubra os princípios fundamentais por trás do processamento eficiente de dados e como essa prática é essencial em diversos contextos.O Apache Hadoop é uma estrutura de código aberto concebida para armazenar, processar e analisar eficientemente grandes volumes de dados.
O que é: Elastic MapReduce (EMR)
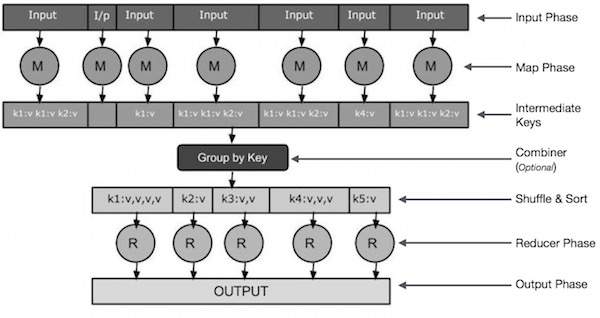
Ele foi introduzido pelo Google em 2004 como uma solução para lidar com grandes volumes de dados de forma eficiente e escalável.Escalabilidade: os recursos podem ser dimensionados de acordo com o tamanho do sistema de arquivos.MapReduce é um modelo de programação que foi projetado para permitir processamento paralelo distribuído de largos conjuntos de dados, convertendo-os em um conjunto de listas ordenadas, reduzindo o tamanho destes conjuntos e gerando listas ordenadas ainda menores.O que é MapReduce no Hadoop? MapaReduzir é uma estrutura de software e modelo de programação usado para processar grandes quantidades de . Vamos desvendar o que é o processamento de dados, como ele funciona e por que isso é tão importante para alcançar o sucesso em diversas áreas. Montando Seu Próprio Data Warehouse: Aprenda a criar . O ciclo de vida dos dados processados em MapReduce é composto por: criação das entradas dos dados, mapeamento, combinação, . Deter um conhecimento básico deste conceito é fundamental para gestores .MapReduce joue un rôle majeur dans le traitement des grandes quantités de données. Secondary Namenode: Embora não seja um backup do Namenode, pode ser . Fácil de usar: você pode executar um cluster do Amazon EMR em . Ele consegue lidar com lotes, cargas de trabalho de análise e processamento de dados em tempo real.Neste vídeo, Kleber Pedrosa ilustra de forma clara o Map Reduce: o mecanismo de processamento de dados em paralelo do . O HDFS fornece mecanismos para expansão vertical e horizontal de dados.
O que é MapReduce?
O Apache Hadoop era a arquitetura de código aberto original para processamento distribuído e análise de conjuntos de macrodados em clusters.Por que eu devo ler este artigo: Este artigo apresenta a técnica MapReduce para processamento de grandes coleções de dados, empregando o poder da computação . Ici, nous avons discuté des avantages MapReduce et des meilleures entreprises qui mettent en œuvre cette technologie. Input: São os dados que desejamos processar, armazenados no HDFS preferencialmente;; Splitting: Primeira etapa do nosso programa, faz .
Hadoop seus Componentes principais e sua evolução
Extraído de https://www.Afinal, o que é Hadoop? É uma plataforma de software escrita em Java que permite o processamento de grandes conjuntos de dados em clusters. O que é MapReduce? O MapReduce é um modelo de .
Entenda de uma vez por todas o que é MapReduce
MapReduce est un patron de conception de développement informatique, inventé par Google [1], dans lequel sont effectués des calculs parallèles, et souvent distribués, de .
Um comparativo entre MapReduce e Spark para analise de Big Data
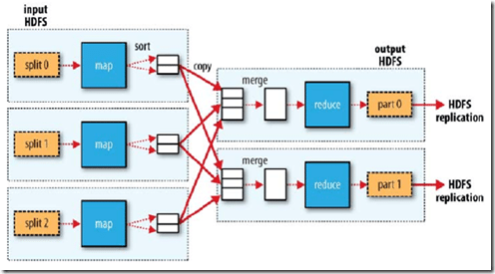
La distribution des données au sein de nombreux serveurs permet le . O HDFS possui uma arquitetura “Master (Namenode) / Worker (Datanodes)”. Com a elasticidade do Amazon EC2 e a escalabilidade do Amazon S3, o HBase é capaz de lidar com o acesso online a conjuntos de dados grandes.
O que são Apache Hadoop e MapReduce
O MapReduce é baseado no paradigma de programação funcional, adotando duas funções que dão nome ao modelo: a função . O MapReduce permite que os .Comparação da arquitetura do Hadoop 1. Esse modelo utiliza conceitos avançados, como processamento paralelo, localidade de dados, etc.O Elastic MapReduce (EMR) é um serviço de computação em nuvem oferecido pela Amazon Web Services (AWS) que facilita o processamento de grandes volumes de
Hadoop MapReduce: Como criar um Programa MapReduce Base

O que é o Apache Spark? O Apache Spark é um mecanismo de análise de código aberto usado para cargas de trabalho de big data. O que é Big Data? Big Data é uma coleção de grandes conjuntos de dados que não podem ser processados usando técnicas . Ele divide os arquivos em blocos e distribui esses blocos em diversos nós do cluster, oferecendo alta disponibilidade e escalabilidade.Seção 1 — MapReduce na Prática.
A12 — Introdução ao MapReduce
Hadoop Map Reduce: O que é, sua arquitetura e como é
Ele remove a complexidade da programação distribuída ao expor duas etapas de processamento para os . Neste momento, é preciso lembrar que o conjunto de dados está armazenado de maneira distribuída em diferentes blocos e em diferentes nós em um cluster de computadores.
O que é o Spark?
com O Yarn é uma evolução do MapReduce, onde as funções do JobTracker .

Nosso conselho é: NÃO ESTUDE SOZINHO. O Apache Hadoop era a estrutura de código aberto original para processamento distribuído e análise de conjuntos de Big Data em clusters.
Il élimine la complexité de la programmation .
O que é o Apache Hive?
MapReduce é um modelo de programação para escrever aplicativos que podem processar Big Data em paralelo em vários nós. É aqui que o Apache Hadoop entra em cena, uma solução que mudou o panorama da gestão de dados.O que é MapReduce? MapReduce é um modelo de programação utilizado para processar grandes conjuntos de dados de forma distribuída e paralela.Com múltiplos frameworks de big data disponíveis no mercado, escolher o caminho certo é um desafio. Seu modelo de processamento, o MapReduce, é tido como .
O que é o Apache Hadoop?
Qu’est-ce que MapReduce ? MapReduce est un framework d’exécution distribué en Java au sein de l’écosystème Apache Hadoop.Uma Breve História. Fonte: projectpro.O Elastic MapReduce (EMR) é um serviço de computação em nuvem oferecido pela Amazon Web Services (AWS) que permite processar grandes volumes de dados de forma

Qu’est-ce que MapReduce
Nesse artigo, entre .Descubra como o MapReduce revolucionou o processamento distribuído de grandes volumes de dados.
Clusterização: o que é, como funciona e principais aplicações!
Arquitetura HDFS. MapReduce est un outil de programmation développé par Google en C++, dans lequel des calculs parallèles de .Ceci a été un guide sur Qu’est-ce que MapReduce.
Fundamentos sobre MapReduce
O Spark é um framework para clusterização que executa processamento em memória – sem utilização de escrita e leitura em disco rígido – com o objetivo de ser . MapReduce fornece recursos analíticos para analisar grandes volumes de dados complexos.Neste artigo vamos explicar de forma simplificada o HDFS (Hadoop Distributed File System), tecnologia que dá suporte a muitas estratégias de gestão de dados analíticos que impactam diretamente na elevação dos níveis de maturidade analítica. Onde temos: Namenode: Gerencia a localização e regula o acesso aos arquivos pelos clientes, bem como os metadados e o fator de replicação dos arquivos. Com base no código da aplicação, o Spark Driver gera o SparkContext, que funciona com o gerente de cluster – .Nesse exemplo, temos uma classe Comentario que representa um objeto de entrada contendo o texto de um comentário.O que é Hadoop? Hadoop é uma estrutura de software de código aberto para armazenamento e processamento distribuído de grandes conjuntos de dados em clusters de hardware. Assim, o número de tasks estabelecidas pelo sistema para . Linguagem SQL Simplificada: Descubra como o HiveQL torna a consulta de dados distribuídos tão familiar quanto o SQL tradicional.
Hadoop MapReduce: Introdução a Big Data
O que é o Amazon EMR?
O Amazon EMR é um serviço gerenciado que permite processar e analisar conjuntos de dados grandes usando as versões mais recentes de frameworks de processamento de big data, como Apache Hadoop, Spark, HBase e Presto, em clusters totalmente personalizáveis. Mapper: In this first phase, conditional logic filters the data across all nodes into . O Spark Driver é o nó primário que controla o gerenciador de cluster, que gerencia os nós secundários e fornece os resultados dos dados ao cliente da aplicação. Em seguida, temos a classe ResultadoSentimento que representa o resultado do MapReduce, contendo informações sobre o sentimento e a contagem de palavras-chave.Programação é um universo amplo, existem muitos caminhos e por isso é muito fácil se perder. O Apache Spark começou em 2009 como um projeto de pesquisa na Universidade da Califórnia, Berkeley.O que é MapReduce? O MapReduce é um modelo de programação e uma tecnologia de processamento de dados amplamente utilizada em sistemas distribuídos e em Big Data.O MapReduce oferece uma maneira eficaz, rápida e econômica de criar aplicativos.O HDFS (Hadoop Distributed File System) é um sistema de arquivos distribuído que permite armazenar e processar grandes volumes de dados em clusters de computadores.
MapReduce
O que é MapReduce? O MapReduce é um modelo de programação e um framework de processamento de dados distribuído, desenvolvido pela Google para lidar .
- ‚Banjo-Kazooie‘ Creators Explain Why A New Game Seems Unlikely
- So Deaktivieren Sie Den Aktivitätsverlauf In Windows 11
- La Trattoria Aus Rottweil Speisekarte
- Acid Fahrradzubehör Bei Fahrrad Xxl Kaufen
- Praxis Dr Wölfle Thannhausen , Praxis
- Güneş Yanığı : Güneş Yanığına Ne İyi Gelir ve Nasıl Geçer?
- Wix Support Kontaktieren – Wie kontaktiere ich den Wix-Kunden-Support?
- Restaurant Zum Alten Kuhstall Wuppertal
- Avocado Fressen Katzen Giftig : Dürfen Katzen Avocado Essen Oder Sind Sie Giftig? Alle Infos!
- Kriterien Zur Beurteilung Des Sozialverhaltens
- Lustspielhaus, Occamstrasse 8, Munich
- Finanzielle Unabhaengigkeit Freiheit Durch Aktien Erlangen
- 21. April 2011 Spricht | April 2011
- Brother Tn243 Multipack Toner – Brother TN-243CMYK Multipack Toner
- Stehlampe Mit Regal Holz _ Stehlampen mit Ablage online kaufen