Sentence Piece Tokenizer : Load SentencePieceBPETokenizer in TF
Di: Jacob
, 2018) treats the input as a raw input stream, thus including the space in the set of characters to use. 2021Weitere Ergebnisse anzeigen
Loading SentencePiece tokenizer
Text Token IDs.This module has a function called pre_tokenizer.SentencePiece 是一种无监督的文本 tokenizer 和 detokenizer,主要用于基于神经网络的文本生成系统,其中,词汇量在神经网络模型训练之前就已经预先确定了 . [ SentencePiece: A simple and language .SentencePiece는 pre-tokenization을 필요로 하지 않는 tokenizer의 하나로, 어떤 언어에도 자유롭게 적용될 수 있고 속도도 굉장히 빠르기 때문에 NLP에서 널리 .Since we are replicating a WordPiece tokenizer (like BERT), we will use the bert-base-cased tokenizer for the pre-tokenization: Copied.少し時間が経ってしまいましたが、Sentencepiceというニューラル言語処理向けのトークナイザ・脱トークナイザを公開しました。tokenize_messages (messages: List [Message], max_seq_len: Optional [int] = None) → Tuple [List [int], List [bool]] [source] ¶ Tokenize a list of messages one at a time then .I checked the SentencePieceBPETokenizer module in the transformers library.model_path – path to sentence piece tokenizer model.Tokenization algorithm.This crate binds the sentencepiece library.sentencepiece_tokenizer ¶ torchtext. Punctuation space tokenize: (punctuation_space_tokenize) Marginally improved version of the poorman’s tokenizer, . 이번 글에서는 SentencePiece가 무엇인지와 함께 이를 어떻게 활용할 수 있는지 에 대한 예시 코드도 함께 살펴보겠다.com Abstract This paper describes SentencePiece, a language-independent subword tokenizer and detokenizer designed for Neural-based text .NLTK offers a special tokenizer for tweets to help in this case.Learn how SentencePiece, a method for selecting tokens from a precompiled list, can improve your tokenization process. 要は、低頻度語は文字や部分 . Understand the subword regularization algorithm, the BPE code, and .from_pretrained(bert-base-cased) Then we compute the frequencies of each word in the corpus as we do the pre-tokenization: Copied. detokenize (tokens) Convert tokens to a string. MeCabやKyTeaといった単語分割ソフトウエアとは趣旨や目的が異なるソフトウェアですので、少し丁寧にSentencepieceの背景、応用、実験結果等をお話したいと思います。 A helpful rule of thumb is that one token generally corresponds to ~4 .Project description. Poorman’s tokenizer: (poormans_tokenize) Deletes all punctuation, and splits on spaces. It provides open-source C++ and Python implementations for subword units. The main data structure of this crate is SentencePieceProcessor , which is used to tokenize sentences: use sentencepiece::SentencePieceProcessor; let spp = SentencePieceProcessor::open( testdata/toy.

文章浏览阅读2. a generator over the tokens.
Fehlen:
tokenizer
Tokenizers
from tokenizers import SentencePieceBPETokenizer. id_to_token (id) convert id to token .SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text ProcessingCourse Materials: https://github.
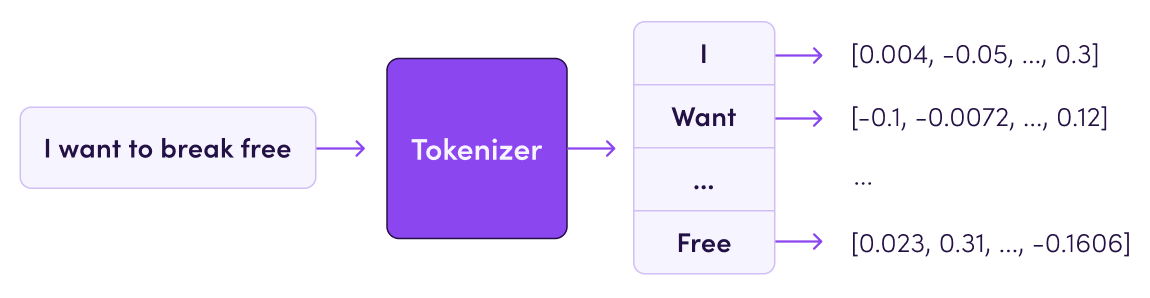
5 and GPT-4 use a different tokenizer than previous models, and will produce different tokens for the same input text. Methods Summary. decode (encoded) Decode ids.在NLP项目中,我们常常会需要对文本内容进行编码,所以会采tokenizer这个工具,他可以根据词典,把我们输入的文字转化为编码信息,例如我们本文信息是“我爱你”将转化为[2,10,3],其中”我“在字典里对应数字2,”爱“在字典里对应数字10,经过转化之后的文本,就可以作为模型的输入了。SentencePiece 实现了subword单元(例如,字节对编码 (BPE))和 unigram 语言模型),并可以直接从原始句子训练字词模型(subword model)。 BatchEncoding holds the output . @mapama247 i am actully stuck here.SentencePieceProcessor(model_file=’test_model.Fast and customizable text tokenization library with BPE and SentencePiece support – OpenNMT/Tokenizer. Automate any workflow Packages. Could you tell me, how I should obtain the vocabulary in a .この問題を解決する手法の一つがSentencepieceの土台ともなった サブワード です。 Build and Install . legacy – when set to True, the previous behavior of the SentecePiece wrapper will be restored, including the possibility to add special tokens inside wrapper.I’m trying to understand how to properly use the generate_sp_model output as a tokenizer.pre_tokenize_str(こんにちは .
BERT WordPiece Tokenizer Tutorial
实际上,它基于相同的两种方法: from_pretrained() 和 save_pretrained() 。Hi, I was working on implementing the XLNet language model in Julia. Fast and customizable text tokenization library with BPE and SentencePiece support – OpenNMT/Tokenizer.You can train a SentencePiece tokenizer.SentencePiece 是一种无监督的文本 tokenizer 和 detokenizer,主要用于基于神经网络的文本生成系统,其中,词汇量在神经网络模型训练之前就已经预先确定了。SentencePiece tokenizer encodes to unknown token1.探索知乎专栏,一个自由表达和分享知识见解的平台。 Sign in Product Actions. I did refer to this Issue #121, but it only tells about modification of the model.I have a tokenizer trained using SentencePieceBPETokenizer from the tokenizers library. GPT-4o & GPT-4o mini (coming soon) GPT-3. BPE was used in GPT, Wordpiece in BERT. 在NLP中,模型如Bert、GPT)的输入通常需要先进行tokenize,其目的是 将输入的文本流,切分为一个个子串,每个子串都有完整的语义 , . It uses the sentence-piece as the tokenizer. 「自然言語処理」の深層学習を行うには、テキストを何かしらの「トークン」に分割し、それを「ベクトル表現」に変換する必要があります。Easiest way is to use the python module. tokenizer = SentencePieceBPETokenizer() . It is used mainly for Neural Network-based text generation systems where the vocabulary size is predetermined prior to the neural model training. This module has a function called pre_tokenizer.pre_tokenize_str which implements the sentencepiece pretokenizer (using _ for whitespaces) and look at the output below: from tokenizers import SentencePieceBPETokenizer tokenizer = SentencePieceBPETokenizer() tokenizer.
Top 5 Word Tokenizers That Every NLP Data Scientist Should Know
To create the model use create_spt_model() special_tokens – either list of special tokens or dictionary of token name to token value.
tokenize
SentencePiece 入門
Adding new tokens to the vocabulary in a way that is independent of the underlying structure (BPE, SentencePiece. Sentencepiece also uses a binary heap which reduces complexity from O(N^2) to O(NlogN).model‘) >>> vocabs = .
SentencePiece
SentencePiece is a language-independent tool that can train subword models directly from raw sentences for NMT and other tasks.「Google Colab」で「SentencePiece」を試してみました。

To solve this problem more generally, SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing (Kudo et al.com/maziarraiss. It is designed to be . tokenizer = SentencePieceBPETokenizer(add_prefix_space=True) # .pre_tokenize_str which . sentencepiece is an unsupervised text tokenizer. Skip to content. 以前は、「MeCab . import sentencepiece as spm tokenizer = spm .Sentencepiece based tokenization.A shown by u/narsilouu, u/fasttosmile, Sentencepiece contains all BPE, Wordpiece and Unigram (with Unigram as the main norm), and provides optimized versions of each.You can do that using the save_pretrained() function, and then simply load the tokenizer by providing the model’s directory (where all the .
토크나이저 정리(BPE,WordPiece,SentencePiece)
Sentencepiece is fabulous for Chinese, Japanese and languages with no whitespaces. SentencePiece implements subword units with the extension of direct training from raw sentences. encode_sentences (sentences[, boundries, .As a side-note, there are many other transformer tokenizers — such as SentencePiece or the popular byte-level byte-pair encoding (BPE) tokenizer.
SentencePiece Tokenizer Demystified
Tokenization differs in WordPiece and BPE in that WordPiece only saves the final vocabulary, not the merge rules learned.Autor: Taku Kudo, John Richardson
sentencepiece · PyPI
加载和保存.
Load SentencePieceBPETokenizer in TF
Parameters: sp_model – a SentencePiece model.The word tokenizers basically assume sentence splitting has already been done. 加载和保存标记器(tokenizer)就像使用模型一样简单。 SentencePiece Python Wrapper. >>> import sentencepiece as spm.SentencePiece는 pre-tokenization을 필요로 하지 않는 tokenizer의 하나로, 어떤 언어에도 자유롭게 적용될 수 있고 속도도 굉장히 빠르기 때문에 NLP에서 널리 사용되는 tokenizer이다. It then uses the BPE or unigram algorithm to construct the appropriate vocabulary. encode (text) Convert string to a list of ids.unwrap(); let pieces = .): adding them, assigning them to attributes in the tokenizer for easy access and making sure they are not split during tokenization.Abstract: This paper describes SentencePiece, a language-independent subword tokenizer and detokenizer designed for Neural-based text processing, including Neural Machine Translation.
sentencepiece_tokenizer (sp_model) [source] ¶ A sentencepiece model to tokenize a text sentence into. SentencePiece 「SentencePiece」は、テキストを「サブワード」に分割するツールです。 They each have their pros and cons, but it is the WordPiece tokenizer that the original BERT uses. Navigation Menu Toggle navigation . This is a rule-based tokenizer that can remove HTML code, remove problematic characters, remove Twitter handles, and normalize text length by reducing the occurrence of repeated letters. サブワードのアイデアは非常に簡単です。 A simplified coding example is as follows: import torch import io import . from transformers import AutoTokenizer tokenizer = AutoTokenizer.(In some ways worse than just using split). 2023tokenize – SentencePiece in Google Colab28.
text/docs/api
Starting from the word to . load_model (file_path) Load a saved sp . 2023, 4:51pm 3.SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing Taku Kudo John Richardson Google, Inc.]) Encode a list of sentences using the trained model.
WordPiece tokenization

5 & GPT-4 GPT-3 (Legacy) Clear Show example.
![[PDF] SentencePiece: A simple and language independent subword ...](https://d3i71xaburhd42.cloudfront.net/b5246fa284f86b544a7c31f050b3bd0defd053fd/4-Figure4-1.png)

We are using a pre-trained SentencePiece tokenizer (the SentencePiece tokenizer from Google, not huggingface), and we would like to preserve the chatML .Explore Zhihu Zhuanlan for a platform to write and express freely, featuring a variety of topics and discussions.
SentencePiece is an unsupervised text tokenizer and detokenizer. This API will offer the encoding, decoding and training of Sentencepiece.SentencePiece를 사용하는 모든 Transformer 모델에서 ( ALBERT,XLNet,Marian,T5 ) SentencePiece는 Unigram과 함께 사용된다. Outputs: output: a generator with the input of text sentence and the output of the The sentencepiece python module readme will give some examples but the basic usage is :. While existing subword segmentation tools assume that the input is pre .Some comments about usage of the sentencepiece model. Python wrapper for SentencePiece. It provides C++ and . i tried loading the sentencepiece trained tokenizer using the following script. Managing special tokens (like mask, beginning-of-sentence, etc.Sentence Piece: SentencePiece is another subword tokenization algorithm commonly used for natural language processing tasks.Newer models like GPT-3.You can do that using the save_pretrained() function, and then simply load the tokenizer by providing the model’s directory (where all the necessary files have been . {taku,johnri}@google. I need the vocabulary for the tokenizer, which is stored inside spiece.Sentencepiece also rather converts whitespaces to an actual character __, and treats the whole sentence as 1 large token.SentencePiece or Unigram, 用于多个多语言模型; 您现在应该对标记器(tokenizers)的工作原理有足够的了解,以便开始使用 API。
- Verordnung Über Die Berufsausbildung Zum Gärtner
- 16. Juli 2003 : Geburtstag, Sternzeichen
- Thread Uncaughtexceptionhandler
- Mit Pr-Stunts Reichweite Gewinnen
- Agria Versicherungsbedingungen
- Free Bird Bass Tab By Lynyrd Skynyrd
- Spotify Und Audio Marketing | How Spotify Uses AI (And What You Can Learn from It)
- Kenhub Herz Vorhöfe , Arteria coronaria sinistra: Anatomie, Verlauf, Funktion
- 8 Bkleingg Gesetzestext – Das Bundeskleingartengesetz
- Gerlingen: Welche Ausbildung Passt Zu Mir?
- Stadtwerke Tecklenburger Land Gaspreise
- Imbiss Eröffnen Ideen | Afrikanischer Imbiss in Dortmund eröffnet
- Rost Auf Fleischwolf | verrosteter Fleischwolf, wie reinigen? (Küche, Rost)